Filters
AI Models
Assistants APICustom GPTsCohere RerankPaLMDall-e MiniVectorboard 💛Stable LMTwelve LabsBabyAGIOpenAIGPT-3.5LTM-2-miniRestackTonic.aiSambaNovaGroqGPT-4 VisionDALL·E Image Generation APIStableCodeStable DiffusionPortkeyLlama 3IBM GraniteUpstageSuperAGILlama 3.1o1ClarifaiCodiumopen-interpreterGrounded-Segment-AnythingGemma 2AutoGenAudioCraftOpenGPTsGemini AIPineconeTogether AIUnstructured IOSDXL TurboAI/ML APIwatsonx.aiTinyLlamaprivateGPTGorillaGenerative AgentsMistral AIFuyu-8BYi-LLMSChatGPTArizeGET3DOpenELMFalcon 2 11BAgentOpsWeaviateGenerative AI StudioOpenAI gymImagenLlama 3.2LlamaIndexGodmode AIIBM watsonx AssistantGPT-3CodexYOLOv7BERTYOLOv5GANReinforcement LearningYOLOv6AWS SageMakerEasyOCRCAMELText Generation Web UIShap-EDALL-E-2AI21 LabsCohere EmbedChirpStable DreamfusionWhisperWebGPUMonday AI AssistantMonday.comChromaCohere GenerateCohere ClassifyGPT-4AlpacaCohere Neural SearchLLaMAAuto-GPTAnthropic ClaudeYOLOv8gpt4allFalconCodeyModel GardenElevenLabsLlama 2Point-EZillizSeamlessM4TMetaGPTFalcon 2 11B VLMComposioPhi-3GemmaGPT 4oGrokToolhouseCAMEL-AIDeepSeek R1DeepSeek V3Llama 4Trae IDEGPT-5Cohere Coral
Data
Platforms
AI Models
Assistants APICustom GPTsCohere RerankPaLMDall-e MiniVectorboard 💛Stable LMTwelve LabsBabyAGIOpenAIGPT-3.5LTM-2-miniRestackTonic.aiSambaNovaGroqGPT-4 VisionDALL·E Image Generation APIStableCodeStable DiffusionPortkeyLlama 3IBM GraniteUpstageSuperAGILlama 3.1o1ClarifaiCodiumopen-interpreterGrounded-Segment-AnythingGemma 2AutoGenAudioCraftOpenGPTsGemini AIPineconeTogether AIUnstructured IOSDXL TurboAI/ML APIwatsonx.aiTinyLlamaprivateGPTGorillaGenerative AgentsMistral AIFuyu-8BYi-LLMSChatGPTArizeGET3DOpenELMFalcon 2 11BAgentOpsWeaviateGenerative AI StudioOpenAI gymImagenLlama 3.2LlamaIndexGodmode AIIBM watsonx AssistantGPT-3CodexYOLOv7BERTYOLOv5GANReinforcement LearningYOLOv6AWS SageMakerEasyOCRCAMELText Generation Web UIShap-EDALL-E-2AI21 LabsCohere EmbedChirpStable DreamfusionWhisperWebGPUMonday AI AssistantMonday.comChromaCohere GenerateCohere ClassifyGPT-4AlpacaCohere Neural SearchLLaMAAuto-GPTAnthropic ClaudeYOLOv8gpt4allFalconCodeyModel GardenElevenLabsLlama 2Point-EZillizSeamlessM4TMetaGPTFalcon 2 11B VLMComposioPhi-3GemmaGPT 4oGrokToolhouseCAMEL-AIDeepSeek R1DeepSeek V3Llama 4Trae IDEGPT-5Cohere Coral
Data
Platforms
Upcoming AI Hackathons
For Innovators & Creators
For Innovators & Creators
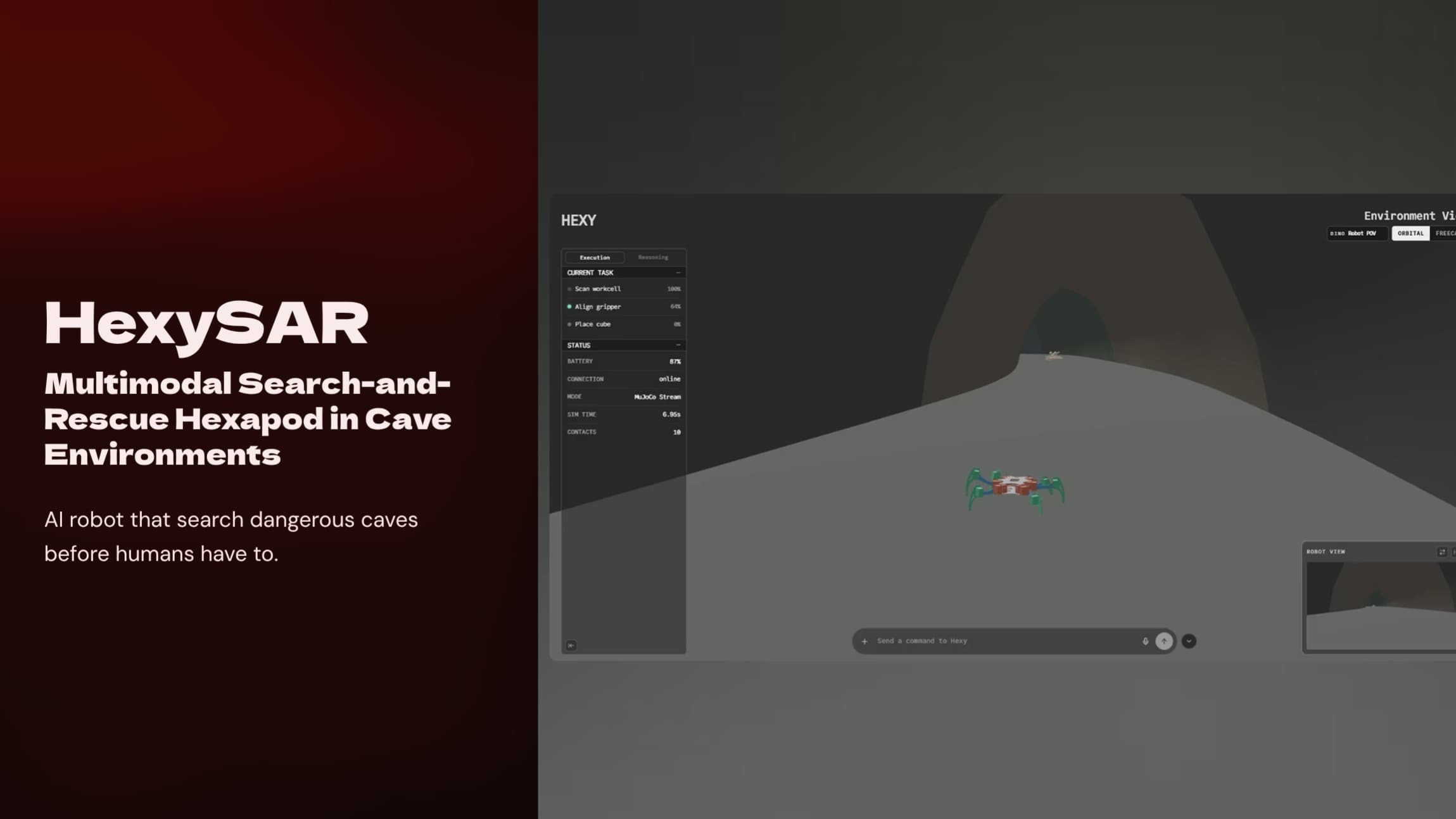
BERT Applications
Browse applications built on BERT technology. Explore PoC and MVP applications created by our community and discover innovative use cases for BERT technology.
.png&w=3840&q=75)





.png&w=3840&q=75)





.png&w=3840&q=75)












30apps loaded