TruLens + Google Cloud Vertex AI Tutorial: Building RAG Applications
TruLens + Google Cloud Vertex AI Tutorial: Building RAG Applications
🌌 Introduction: Unveiling the World of TruLens and AI
Hello and welcome to an enriching journey through the realms of artificial intelligence! In this extensive tutorial, we are going to dive deep into the capabilities of TruLens and Google Cloud Vertex AI. Whether you're a beginner in AI or someone looking to expand your skills, this guide will provide you with a comprehensive understanding of how to build intelligent, context-aware applications. Our focus will be on creating a Retrieval-Augmented Generation (RAG) system, a type of application that combines the power of information retrieval and language generation to answer questions in a way that's both accurate and contextually rich.
🚀 Exploring TruLens and Its Capabilities
TruLens is a powerful tool that provides valuable insights into the inner workings of AI models. It stands out for its ability to make AI decision-making transparent, allowing developers to understand and improve their models effectively. In the world of AI where explanations are often as crucial as outcomes, TruLens is your ally in decoding the 'why' and 'how' behind your model's responses.
Key Features of TruLens:
- Insightful Interpretability: 🕵️♂️ Dive deep into the model's decision-making process, understanding the rationale behind each response.
- Performance Analytics: 📊 Access detailed metrics that shed light on how well your model is performing against various benchmarks.
- Iterative Improvement: 🔁 Use the insights gained from TruLens to fine-tune and enhance your AI model, ensuring it not only meets but exceeds expectations.
🛠 Part 1: Setting Up Your Development Environment
Step 1: Importing Libraries
import os
import requests
import streamlit as st
import weaviate
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatVertexAI
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.memory import ConversationSummaryMemory
from langchain.prompts import ChatPromptTemplate
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Weaviate
from trulens_eval import Feedback, Huggingface, Tru, TruChain
from weaviate.embedded import EmbeddedOptions
- Why These Imports?
osandrequests: For interacting with the operating system and fetching data from URLs.streamlit: To create an interactive web application for your RAG system.weaviate: A database client for handling vectorized data, crucial for RAG applications.
Step 2: Environment Configuration
from dotenv import load_dotenv
load_dotenv()
- Loading Environment Variables: Securely manage your API keys and configurations using environment variables.
Step 3: Setting API Keys
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = os.getenv("GOOGLE_APPLICATION_CREDENTIALS")
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["HUGGINGFACE_API_KEY"] = os.getenv("HUGGINGFACE_API_KEY")
- API Configuration: These lines are crucial for accessing services like Google Cloud Vertex AI, OpenAI, and Huggingface.
🤖 Part 2: Initializing Core AI Components
Step 4: Initializing Huggingface and TruLens
hugs = Huggingface()
tru = Tru()
- Why Huggingface and TruLens?
Huggingface: Provides NLP functionalities necessary for processing language.TruLens: Monitors and enhances the AI model’s performance.
Step 5: Setting Up Chain Recorder and Conversation
chain_recorder = None
conversation = None
def handle_conversation(user_input):
input_dict = {"question": user_input}
try:
with chain_recorder as recording:
response = conversation(input_dict)
return response.get("answer", "No response generated.")
except Exception as e:
return f"An error occurred: {e}"
- Preparation for Conversational AI: These components, once initialized, will manage the logic and recording of AI interactions.
🌐 Part 3: Creating the User Interface with Streamlit
Step 6: Streamlit Sidebar for URL Input
st.sidebar.title("Configuration")
url = st.sidebar.text_input("Enter URL")
submit_button = st.sidebar.button("Submit")
- Interactive UI Setup: This step allows users to input a document URL, which the RAG system will use.
📚 Part 4: Data Processing and RAG System Setup
Step 7: Handling Document Loading and RAG Initialization
if 'initiated' not in st.session_state:
st.session_state['initiated'] = False
st.session_state['messages'] = []
if submit_button or st.session_state['initiated']:
st.session_state['initiated'] = True
if url and not conversation:
# Load and process the document
res = requests.get(url)
with open("state_of_the_union.txt", "w") as f:
f.write(res.text)
loader = TextLoader('./state_of_the_union.txt')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
client = weaviate.Client(embedded_options=EmbeddedOptions())
vectorstore = Weaviate.from_documents(client=client, documents=chunks, embedding=OpenAIEmbeddings(), by_text=False)
retriever = vectorstore.as_retriever()
llm = ChatVertexAI()
template = """You are an assistant for question-answering tasks..."""
prompt = ChatPromptTemplate.from_template(template)
memory = ConversationSummaryMemory(llm=llm, memory_key="chat_history", return_messages=True)
conversation = ConversationalRetrievalChain.from_llm(llm, retriever=retriever, memory=memory)
chain_recorder = TruChain(
conversation,
app_id="RAG-System",
feedbacks=[
Feedback(hugs.language_match).on_input_output(),
Feedback(hugs.not_toxic).on_output(),
Feedback(hugs.pii_detection).on_input(),
Feedback(hugs.positive_sentiment).on_output(),
]
)
- Conditional Data Loading: This block ensures the RAG system initializes only after a document URL is provided.
💬 Part 5: Building the Conversational Interface
Step 8: Streamlit Frontend for User Interaction
st.title("RAG System powered by TruLens and Vertex AI")
# Display chat messages
for message in st.session_state.messages:
st.write(f"{message['role']}: {message['content']}")
# User input and response handling
user_prompt = st.text_input("Your question:", key="user_input")
if st.button("Send", key="send_button"):
# Add user message to chat history
st.session_state.messages.append({"role": "user", "content": user_prompt})
# Generate and display assistant response
assistant_response = handle_conversation(user_prompt)
# Update and display chat history
st.session_state.messages.append({"role": "assistant", "content": assistant_response})
st.write(f"Assistant: {assistant_response}")
# Run TruLens dashboard
tru.run_dashboard()
else:
st.write("Please enter a URL and click submit to load the application.")
- Developing the Chat Interface: This section uses Streamlit to create a platform where users can interact with the RAG system.
📊 Part 6: Integrating TruLens for Insights
Step 9: Deploying the TruLens Dashboard
tru.run_dashboard()
- Performance Tracking: The TruLens dashboard provides real-time insights into the RAG system's performance, aiding in continuous improvement.
By the end of this tutorial, you'll have a comprehensive understanding of creating an intelligent RAG application using state-of-the-art tools. This journey will equip you with the skills to innovate and push the boundaries in the field of AI. Let's embark on this exciting path together! 🚀👨💻🌍
Paste the link
Main Screen
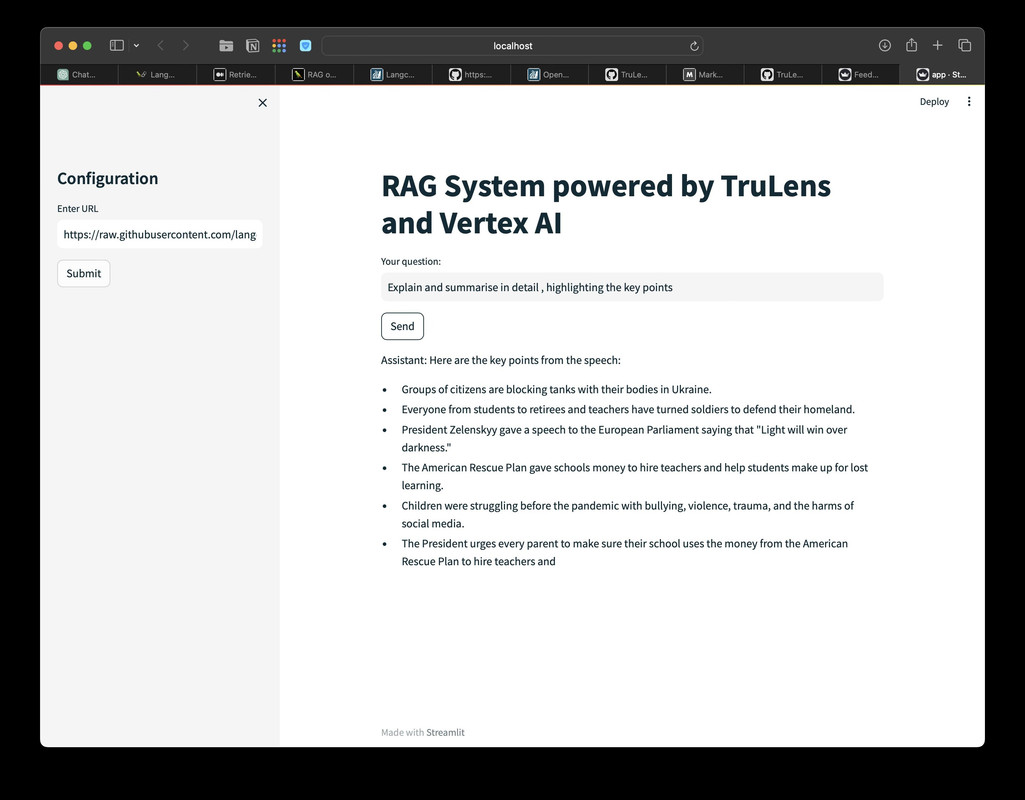
Answers fetched through RAG
🔍 Enhancing Performance with TruEra
With our prototype in place, it's time to introduce TruEra. This tool helps us to not just build, but to refine. TruEra provides an in-depth look into our application's performance, allowing us to identify how well it's responding to real-world data and user interactions.
Implementing TruEra:
The implementation of TruEra involves setting up key metrics relevant to our RAG application. These metrics will help us understand various aspects of performance, from response accuracy to user satisfaction.
📈 Establishing an Evaluation Suite
After our RAG system is up and running, we'll set up an evaluation suite using TruEra. This involves:
- Defining Key Metrics: Select metrics that best represent the success and efficiency of your application.
- Benchmarking: Establish benchmarks to measure against, providing a clear view of where your application stands.
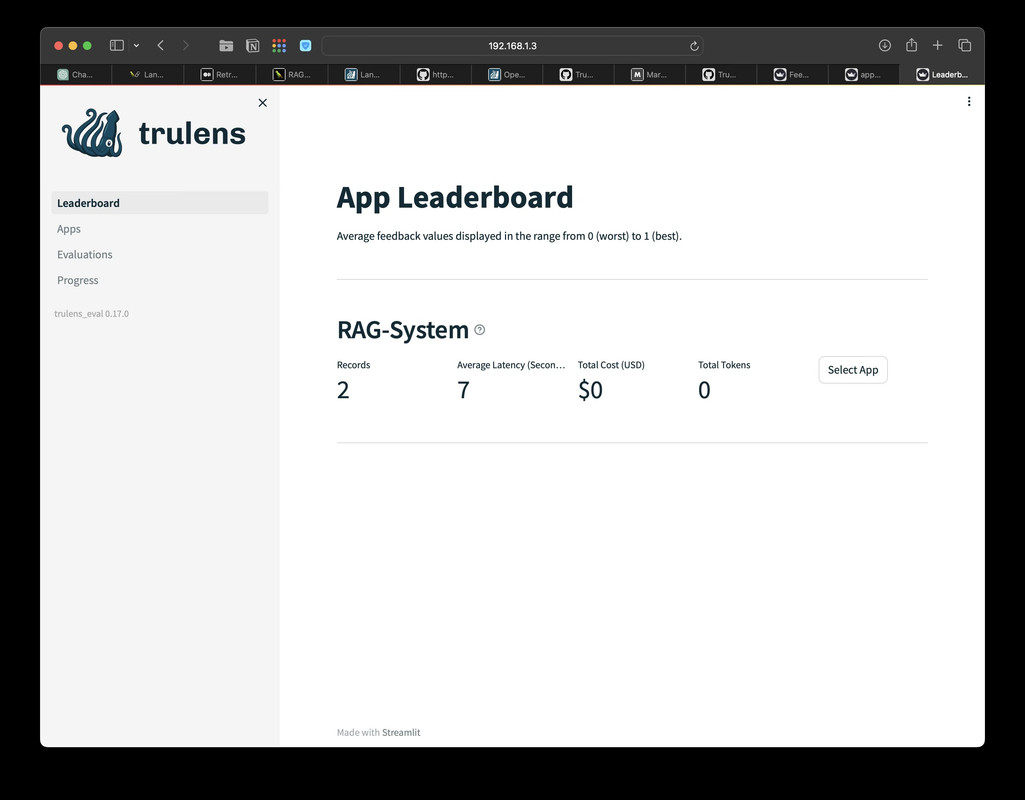
TrueLens Dashboard
App Leaderboard
Evaluations
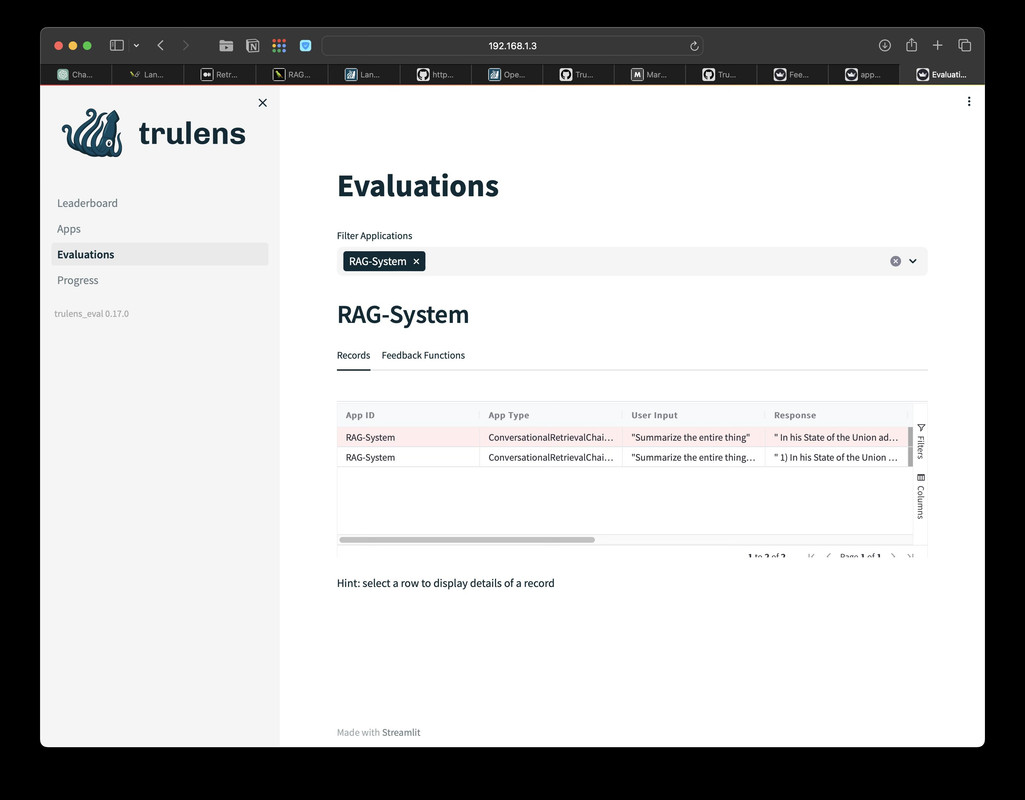
Verify the hash
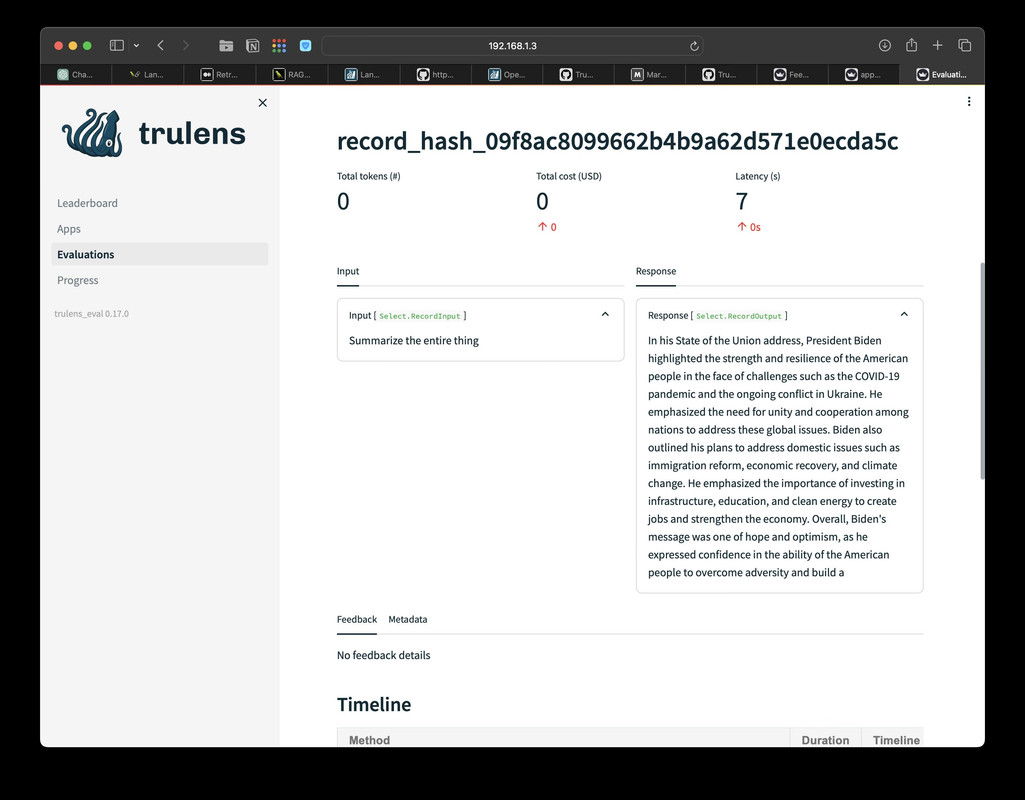
Timeline
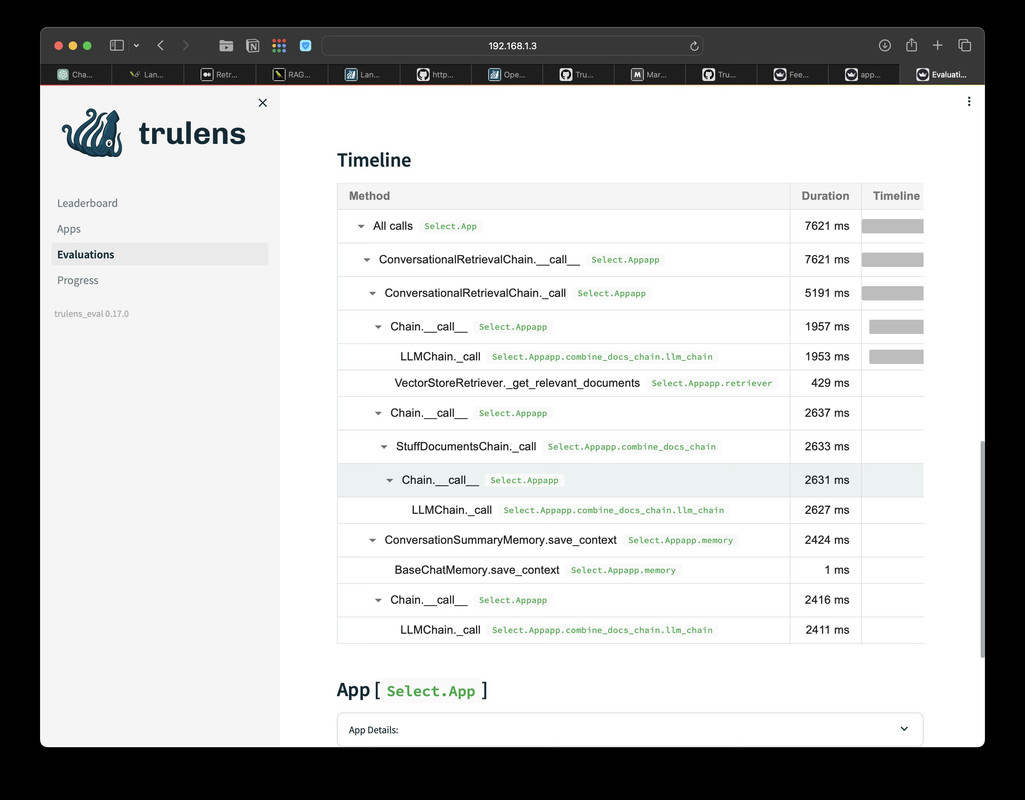
Feedback Progress
Extended logs
🛠 Addressing Underperformance
Armed with data and insights from TruEra, we focus on identifying and improving areas where our RAG application might be underperforming. This stage is crucial for turning a good application into a great one.
Steps for Improvement:
- Data Analysis: Look at the metrics and identify patterns or areas of concern.
- Making Iterative Changes: Implement changes based on your findings and monitor their impact.
🌟 Conclusion: Embracing the AI Development Journey
As we conclude this comprehensive tutorial, take a moment to appreciate the journey you've embarked on. From understanding the basics of TruLens and Google Vertex AI to building a sophisticated RAG application and enhancing it with TruEra, you've traversed a significant learning curve in AI development.
Remember, the field of AI is ever-evolving, and so should our approach to building applications. Continuously learning, adapting, and improving are key to staying ahead in this exciting domain. Your journey in AI doesn't end here; it's just the beginning of endless possibilities and innovations waiting to be discovered.
Embrace your newfound knowledge, experiment, and let your creativity lead the way to new AI adventures! 🚀🤖🌈

