Ian Villanueva@sprites20847
sprites20847
🤓 Latest Submissions
.png&w=828&q=75)
3D Engine for your Humanoid AI Agent
Developing a sophisticated 3D engine for a humanoid AI agent represents the next frontier in embodied artificial intelligence, bridging the gap between abstract large language models and physical reality. At the core of this system is a robust character controller designed to handle complex locomotion and spatial interactions. Unlike traditional video game characters that rely on fixed animations, this agent utilizes a blend of procedural movement and physics-based constraints. This allows the agent to not only walk, run, and jump with fluid transitions but also to interact with its surroundings in a tactile way. By implementing Inverse Kinematics (IK), the agent can accurately reach out and place objects on surfaces of varying heights, ensuring that its hands align perfectly with the environment's geometry. This physical grounding is essential for simulation, as it allows the AI to "feel" the constraints of the 3D space, providing a realistic training ground for tasks that involve manual dexterity and environmental navigation.
10 May 2026

Procedural World with AI NPCs
🧠 Project Pitch: Temporal Multimodal RAG for Lifelong Contextual Understanding ❓ Problem Modern Retrieval-Augmented Generation (RAG) systems excel at processing static text, but they lack context over time, lose multimodal integration, and struggle to link events across different types of data (text, image, audio, video). In critical domains like medicine, law, or security, this limits their ability to reason causally, temporally, or contextually across cases. 💡 Solution We’re developing a Temporal-Aware Multimodal RAG system — an AI memory architecture that models real-time evolving knowledge much like a human brain: “Every memory is a node; every node connects causally and temporally to others — across all senses.” Our system supports: Text, Image, Audio, and Video embeddings Scene-level segmentation for video and audio Causal-temporal linkage between memory nodes OLAP-enhanced SQL backend for flexible and explainable reasoning Unlearning capability, allowing dynamic memory rewriting without full retraining
8 Jul 2025
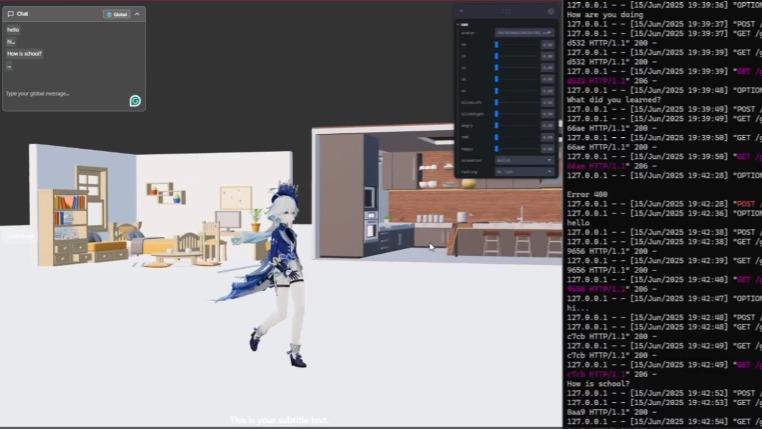
Anim3D Engine
This platform is an extensible AI-integrated game engine designed to enable anyone — from hobbyists to developers — to create interactive games and virtual characters effortlessly. With built-in support for AI agents, creators can give characters unique behaviors, personalities, and the ability to respond to real-time events, player inputs, or narrative triggers. Users can: • 🛠️ Design custom characters with AI-driven decision-making • 🎮 Build games using an intuitive UI and Three.js-based visual editor • 🧠 Integrate LLMs (e.g., Together AI, OpenAI, Claude) for dynamic dialogues and behavior trees • 🗺️ Create immersive worlds with physics, animation, and sound support • 📦 Export/share games or run them in-browser instantly The engine leverages modern web technologies like React Three Fiber, TailwindCSS, and Vite, and supports plugin-like modules for: • Text-to-Speech (TTS) and Speech-to-Text (STT) • Goal-oriented AI agents • Multiplayer via WebSockets
15 Jun 2025
.png&w=828&q=75)
Anim3D
I would like to share my WIP talking 3D characters that will soon integrate Text-To-Speech models and Large Language Models, as well as Audio To Visemes to generate lip-sync data. Like the popular character.ai except they have a physical body. We envision an app that allows people to interact with their AI companion or even their AI companions interacting with the virtual world created for them. Much like Sims 3D or other life simulators. Or even them interacting with other virtual characters. Unfortunately the thing isn't finished yet. I'm just sharing this creation as I may continue on it on the future.
1 May 2025
.png&w=828&q=75)
Autonomous Rocket and Rover Simulator
🌍 Problem: Navigating a rocket autonomously is a complex challenge. Traditional control systems struggle with precision, stability, and adaptability in dynamic environments. Whether for planetary landings, orbital maneuvers, or interplanetary travel, rockets must follow a precise path while adjusting for external forces like gravity, wind, and system disturbances. 💡 Solution: We present an autonomous rocket simulation that leverages a PID (Proportional-Integral-Derivative) controller to dynamically adjust thrust and orientation, ensuring precise path-following and stability. The system is coupled with orbital motion simulation, allowing for realistic spaceflight planning and trajectory optimization. 🚀 How It Works: PID-Controlled Rocket Navigation Uses real-time feedback to correct deviations from the desired path. Adjusts thrust and angle dynamically for smooth, efficient trajectory tracking. Works under different conditions: atmospheric launch, vacuum space maneuvers, and planetary descent. Orbital Motion Simulation Implements Keplerian mechanics and numerical integration to predict orbital trajectories. Models gravitational interactions for accurate spaceflight physics. Allows testing of satellite placement, docking procedures, and re-entry dynamics. Autonomous Path-Following Vehicle Uses AI-based decision-making and PID control to navigate across terrain or space environments. Can be adapted for planetary rovers, drones, or space-based vehicles. 🎯 Why It Matters: Space Missions – Enables autonomous course corrections for efficient satellite launches and planetary landings. AI & Robotics – Advances self-correcting flight and vehicle navigation systems. Education & Research – Provides an interactive tool for aerospace and AI development.
9 Feb 2025
.png&w=828&q=75)
RAG-Powered Societal Solutions Platform
Our platform is an AI-powered solution that equips governments with actionable, evidence-based guidance by leveraging Retrieval-Augmented Generation (RAG). It retrieves relevant research papers, policy documents, and global data, then synthesizes this knowledge into tailored recommendations for complex challenges such as climate resilience, healthcare, and urban development. With dynamic, context-aware insights and continuously updated information, the platform empowers decision-makers to make faster, smarter, and more accountable choices. By providing scalable, interactive support rooted in cutting-edge research, we redefine how governments turn knowledge into impactful policies for a better future.
15 Dec 2024
.png&w=828&q=75)
Medical Recommendations and Diagnostics
We’re introducing a groundbreaking Personalized Medical Plan Generator, designed to deliver customized recommendations for a wide range of categories such as Meal Plans, Medication Plans, Daily Schedules and Tasks, and much more. Whether you’re managing a specific medical condition, aiming for better wellness, or need general health advice, our tool creates personalized plans based on vital factors like age, sex, weight, activity level, and medical history. Powered by cutting-edge AI technology, the platform generates medically accurate, comprehensive, and customized plans that are perfectly tailored to each individual's unique needs. Using newer embedding models like BGE M3 or Jina Embeddings we can utilize it to retrieve related documents for future knowledge distillation of medical data. The server code is also here but is hosted in AWS https://github.com/sprites20/Disease-Ontology-Retrieval
11 Dec 2024
.png&w=828&q=75)
Robotic OS and VLM Chat Website
Vision-Language Models (VLMs) hold immense potential to revolutionize robotics by enabling more intuitive, efficient, and human-like interactions. By combining the power of computer vision and natural language processing, VLMs allow robots to see and understand the world in ways that mimic human perception. Imagine a robot that can not only navigate a room but also follow complex verbal instructions—like "Pick up the red cup from the table"—while accurately interpreting the visual scene. VLMs make this possible by linking language with visual cues, enabling robots to perform tasks like object manipulation, navigation, and task execution seamlessly. In dynamic environments, VLMs give robots the ability to adapt to new situations, learning and evolving through interaction. Whether it's a robot in a factory following an assembly line, a service robot responding to a user's commands, or an autonomous vehicle understanding its surroundings, VLMs empower robots to respond intelligently to both visual and linguistic inputs, making them more flexible and efficient in real-world scenarios. For industries ranging from manufacturing to healthcare, this capability unlocks the potential for multimodal collaboration, where robots work alongside humans in a more natural and intuitive way. By reducing the gap between human language and robotic action, VLMs have the potential to make robots smarter, more adaptive, and capable of performing a wider range of tasks with greater precision and efficiency. The future of robotics is not just about automation—it's about creating robots that can truly understand and interact with the world around them, and VLMs are the key to making that vision a reality.
11 Nov 2024
Multiagent Chatbot with o1
Soon we can chat with o1 on a website with your phone, upload files, and create AI agents. With O1's strong reasoning capabilities, you can have a very intelligent chatbot that can handle multiple servers. We can even create LDB-based agents that can reason before sending outputs, combining a debugger and a Reflexion agent to not only fix bugs correctly but also attempt to improve the code's time and space complexity. We can use it to optimize costs multiple times cheaper if we can also use it to transpile code from 1 language to another like from Python to C++ resulting in 10-100x cheaper costs, especially for cloud deployments like AWS, GCP, or Azure. And translate code to maximize its efficiency. Implementing Language Agent Tree Search (LATS) for optimizing the space complexity and time complexity in combination with the LDB debugger. Both working together will be able to not only solve problems correctly but to also explore better and more efficient and cheaper solutions. Please run the Spirit AGI main.py and go to the website, it will use the localhost as a server in the UI, you load the nodes and then run the nodes https://github.com/sprites20/Spirit-AGI The build code for the website: https://github.com/sprites20/sprites20.github.io Source code of website: https://github.com/sprites20/sprites20.github.io/tree/main/src Website link in presentation
11 Oct 2024


















