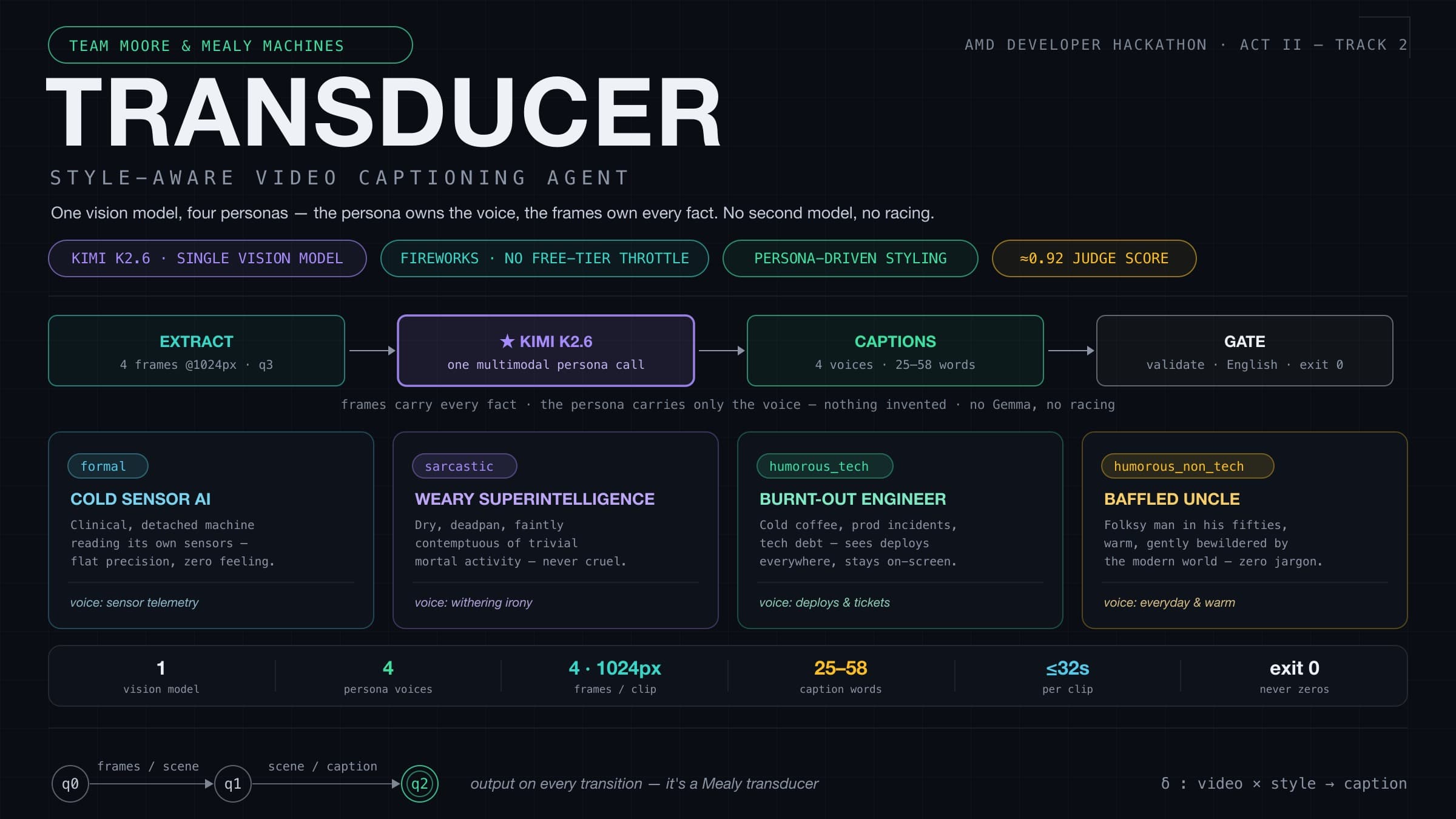
Top Builders
Explore the top contributors showcasing the highest number of app submissions within our community.
Claude Code
Claude Code is an advanced command-line interface (CLI) tool developed by Anthropic, designed to empower its AI model, Claude, with direct code interaction capabilities. This tool allows developers to leverage Claude for agentic coding tasks, including refactoring, debugging, and managing code within the terminal environment. It integrates Claude's powerful language understanding with practical development workflows, bringing AI assistance directly to the codebase.
| General | |
|---|---|
| Author | Anthropic |
| Release Date | 2024 |
| Website | https://code.claude.com/ |
| Documentation | https://code.claude.com/docs/en/overview |
| Technology Type | AI Coding Assistant |
Key Features
- Agentic Coding: Enables Claude to perform complex coding tasks autonomously, guided by natural language instructions.
- Terminal Integration: Works directly within the command line, providing a seamless experience for developers.
- Code Refactoring: Assists in improving code quality, structure, and efficiency.
- Debugging Support: Helps identify and resolve issues in the codebase.
- Code Management: Facilitates various code-related operations, enhancing developer productivity.
- Natural Language Interaction: Developers can interact with Claude using plain language prompts for coding tasks.
Start Building with Claude Code
Claude Code offers a powerful way to integrate Anthropic's Claude AI directly into your coding workflow. By providing agentic capabilities from the terminal, it streamlines refactoring, debugging, and general code management. Developers can leverage this tool to accelerate development, improve code quality, and benefit from AI assistance in real-time.
Anthropic Claude Code AI technology Hackathon projects
Discover innovative solutions crafted with Anthropic Claude Code AI technology, developed by our community members during our engaging hackathons.

.png&w=3840&q=75)