.png&w=256&q=75)
🤓 Latest Submissions
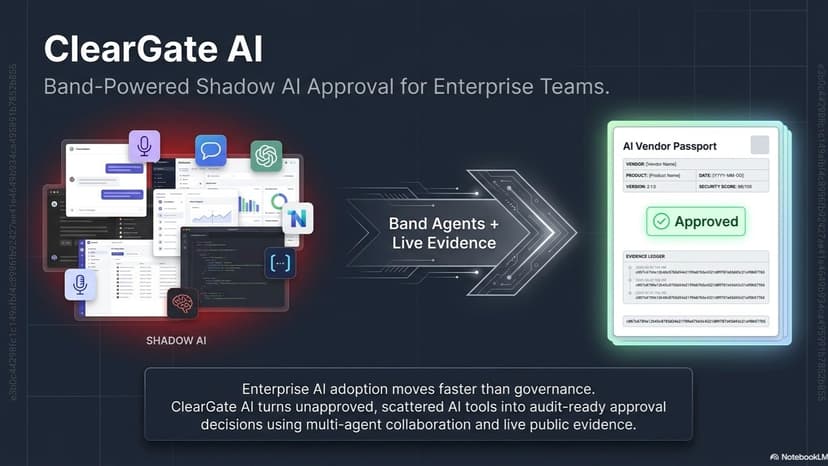
ClearGate AI - Shadow AI approval enterprise.
Problem Employees often adopt AI tools before governance teams can approve them. Security, privacy, procurement, and GRC teams then need fast answers to practical questions: Which unapproved tools are already in use? Which tools touch source code, call recordings, customer notes, contracts, or internal documents? What public evidence supports an approve, conditional approve, escalate, or block decision? Has the vendor documentation or public risk profile changed since the last review? Manual vendor review is slow because trust centers, privacy policies, subprocessor pages, docs, and public risk signals are scattered across the web and change over time. Solution ClearGate AI turns Shadow AI intake into an evidence-backed approval workflow: Shadow AI Inbox -> Band Agent Room -> Live Public Evidence -> Policy Gate -> Decision -> AI Vendor Passport Memo -> Continuous Re-review The current app opens with a deterministic seeded judge workspace containing 11 AI tools, varied risk levels, and varied decisions. Reviewers can import additional tools, run queue review, run a Band agent review, run live verification for a vendor, inspect evidence rows, override decisions, save reviewer notes, and export approval memos. Continuous re-review is implemented as repeatable reviewer-triggered verification through the queue and vendor review flows. There is no background scheduler or database persistence in this build. Band Agent Room The Agent Room tab coordinates six deterministic demo agents over the selected vendor: Discovery Agent Security Agent Privacy & Legal Agent Finance & Procurement Agent Compliance Agent Policy Gate Agent Running the Band review creates a collaboration timeline, shared context packet, recommendation, audit hash, and memo-ready Band Agent Finding evidence records. Human reviewers can explicitly approve with conditions, escalate, or block from the room; those actions are saved into reviewer notes and included in memo/export payloads.
19 Jun 2026
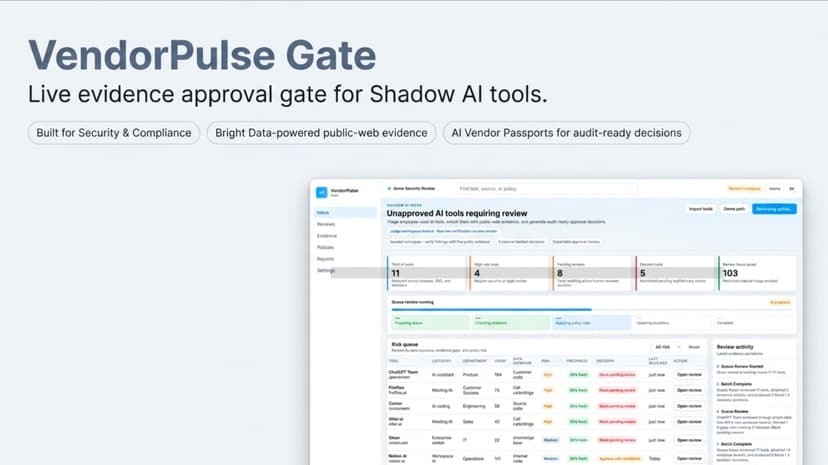
VendorPulse live approval gate for Shadow AI tools
Problem Employees often adopt AI tools before governance teams can approve them. Security, privacy, procurement, and GRC teams then need fast answers to practical questions: Which unapproved tools are already in use? Which tools touch source code, call recordings, customer notes, contracts, or internal documents? What public evidence supports an approve, conditional approve, escalate, or block decision? Has the vendor documentation or public risk profile changed since the last review? Manual vendor review is slow because trust centers, privacy policies, subprocessor pages, docs, and public risk signals are scattered across the web and change over time. Solution VendorPulse Gate turns Shadow AI intake into an evidence-backed approval workflow: Shadow AI Inbox -> Live Public Evidence -> Policy Gate -> Decision -> AI Vendor Passport Memo -> Continuous Re-review The current app opens with a deterministic seeded judge workspace containing 11 AI tools, varied risk levels, and varied decisions. Reviewers can import additional tools, run queue review, run live verification for a vendor, inspect evidence rows, override decisions, save reviewer notes, and export approval memos. Continuous re-review is implemented as repeatable reviewer-triggered verification through the queue and vendor review flows. There is no background scheduler or database persistence in this build.
31 May 2026
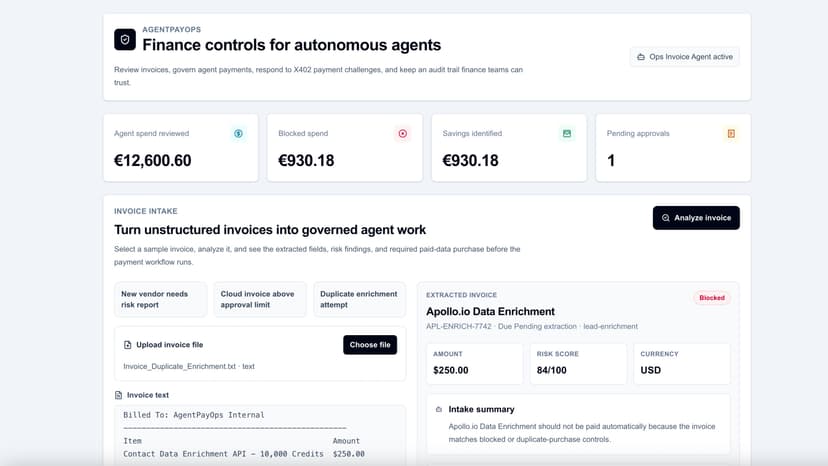
AgentPayOps Finance controls for autonomous agents
Autonomous agents will buy data, tools, compute, and services. Companies need a control plane that decides when those agents are allowed to spend money, blocks risky or duplicate purchases, escalates high-value actions, and records every decision for finance teams. AgentPayOps demonstrates that control layer through one vertical workflow: An invoice agent reviews a vendor invoice. The agent needs a paid vendor-risk report. The report endpoint returns 402 Payment Required. AgentPayOps evaluates vendor, category, amount, approval threshold, and duplicate-purchase rules. The system approves, blocks, or escalates the payment. Transactions and reasoning are shown in an audit dashboard.
19 May 2026
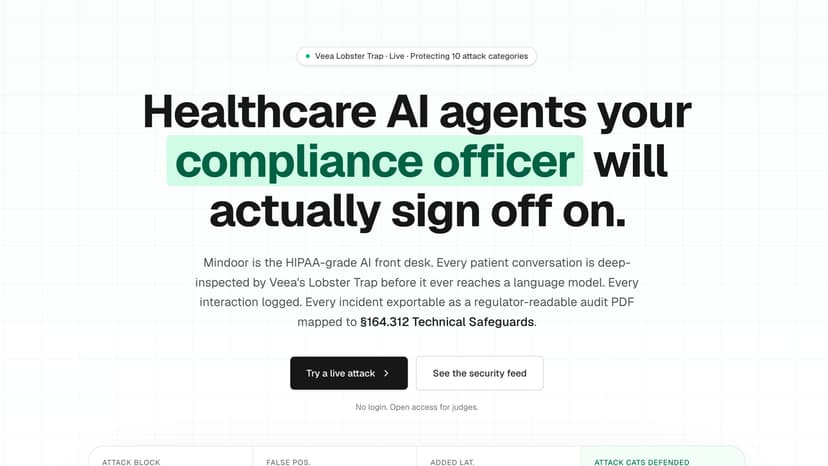
Mindoor — HIPAA-Grade AI Front Desk
The Problem Healthcare and wellness clinics are rushing to adopt AI front-desk agents to reduce burnout and cut costs. But the moment an AI handles a patient conversation, it inherits HIPAA. One successfully injected prompt, one PHI exfiltration, one role-escalation attack — and the clinic has a reportable breach, a $10M average liability, and a CMS audit. Current AI receptionists ship with no policy enforcement, no conversation-layer security, and nothing a compliance officer can sign off on. The Solution Mindoor puts Veea's Lobster Trap in front of every patient conversation as the trust layer. Every message is deep-inspected before it reaches Gemini. Every interaction is logged. Every security incident is exportable as a regulator-readable PDF mapped to HIPAA §164.312 Technical Safeguards.
19 May 2026
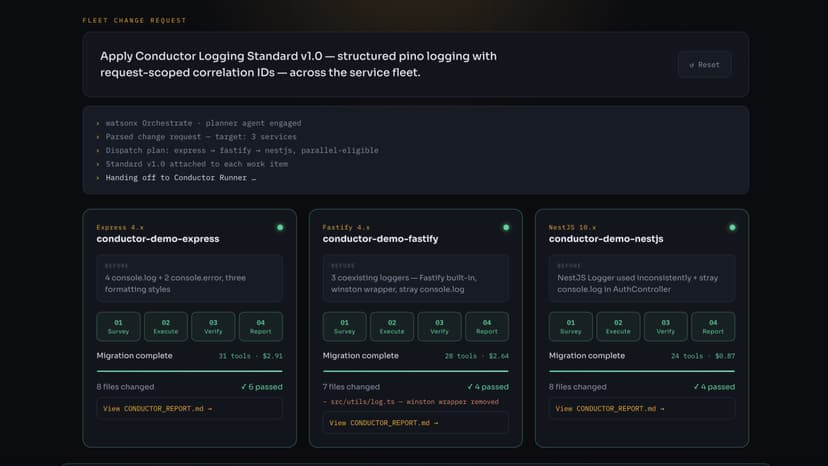
CONDUCTOR - Cross-Repo Consistency Agent
Every engineering team has the same expensive problem: fleet drift. You decide on a new standard — a logging format, a security patch — and now it has to land in dozens of repositories. Each one is different. A script can't reason about those differences. A human can't scale. This is Conductor — a cross-repo consistency agent built on IBM Bob. One change request in, a consistent fleet out. Three services, three frameworks, one standard — applied consistently from a single request. Conductor combines IBM Bob doing the per-repository reasoning with watsonx Orchestrate coordinating the fleet. Fleet drift, solved — by a builder at any skill level. That's Conductor.
17 May 2026
Autopsy investigates why companies fail
What it is Autopsy investigates why companies fail — and what could have saved them. Six specialized AI agents per mode research in parallel, debate each other's findings, and produce a forensic verdict in ~22 seconds. Four modes: Postmortem — investigate why a company failed Pre-Mortem — predict what could kill a living company Founder Mode — analyze your own startup before it fails Counterfactual — explore alternate histories: "What if they made a different decision?" Counterfactual Mode The 4th mode asks: What if [company] had made a different decision? Six counterfactual agents reason about what didn't happen: CF Market Analyst — skeptical about internal decisions changing external market realities CF Operator — assesses whether the alternate decision could actually be executed CF Money Trail — models the financial impact of the alternate path CF Customer Voice — evaluates whether users would have responded differently CF Engineer — honest about technical complexity vs. leadership beliefs CF Historian — finds real precedents (requires 2+ historical cases as evidence) Each agent must: understand the actual causal chain, identify the decision point, model the alternate chain, find real precedents, and assess second-order consequences (butterfly effects). The synthesizer renders one of five verdicts: would have survived, would have delayed failure, would have failed differently, would have made no difference, or could have transformed the company. Preset scenarios: Blockbuster/Netflix, Kodak/Digital, Yahoo/Google, Quibi/TV, Theranos/Real Science, MySpace/Better Tech.
10 May 2026








