Top Builders
Explore the top contributors showcasing the highest number of app submissions within our community.
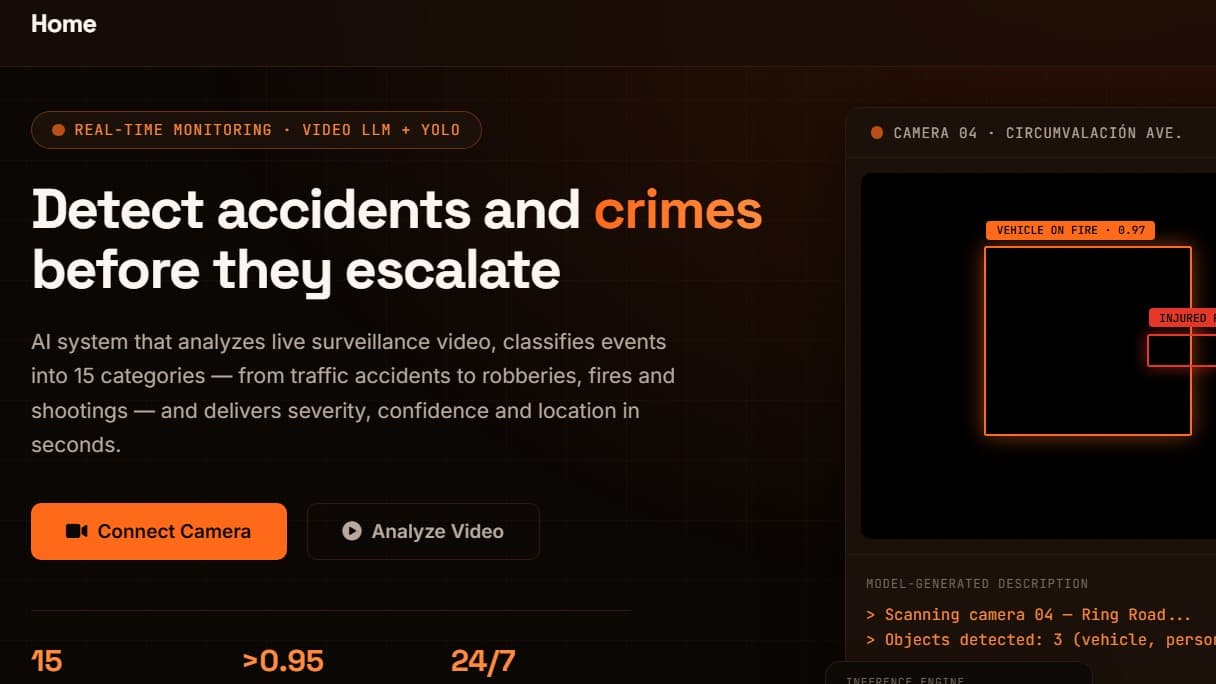
YOLO v8
Ultralytics YOLOv8 is a cutting-edge, state-of-the-art (SOTA) model that builds upon the success of previous YOLO versions and introduces new features and improvements to further boost performance and flexibility. YOLOv8 is designed to be fast, accurate, and easy to use, making it an excellent choice for a wide range of object detection and tracking, instance segmentation, image classification and pose estimation tasks.
What's new in YOLOv8?
YOLOv8 supports a full range of vision AI tasks, including detection, segmentation, pose estimation, tracking, and classification. This versatility allows users to leverage YOLOv8's capabilities across diverse applications and domains.
| General | |
|---|---|
| Relese date | May, 2023 |
| Repository | https://github.com/ultralytics/ultralytics |
| Type | Real time object detection |
Libraries
Discover YOLOv8
- Documentation YOLOv8:
- Quickstart Quickstart with YOLOv8
- GitHub Repository View the GitHub repository for YOLOv8
- Hugging Face Spaces Test YOLOv8 in the browser with Hugging Face Spaces
YOLO YOLOv8 AI technology Hackathon projects
Discover innovative solutions crafted with YOLO YOLOv8 AI technology, developed by our community members during our engaging hackathons.