Probably runs on Samsung S25
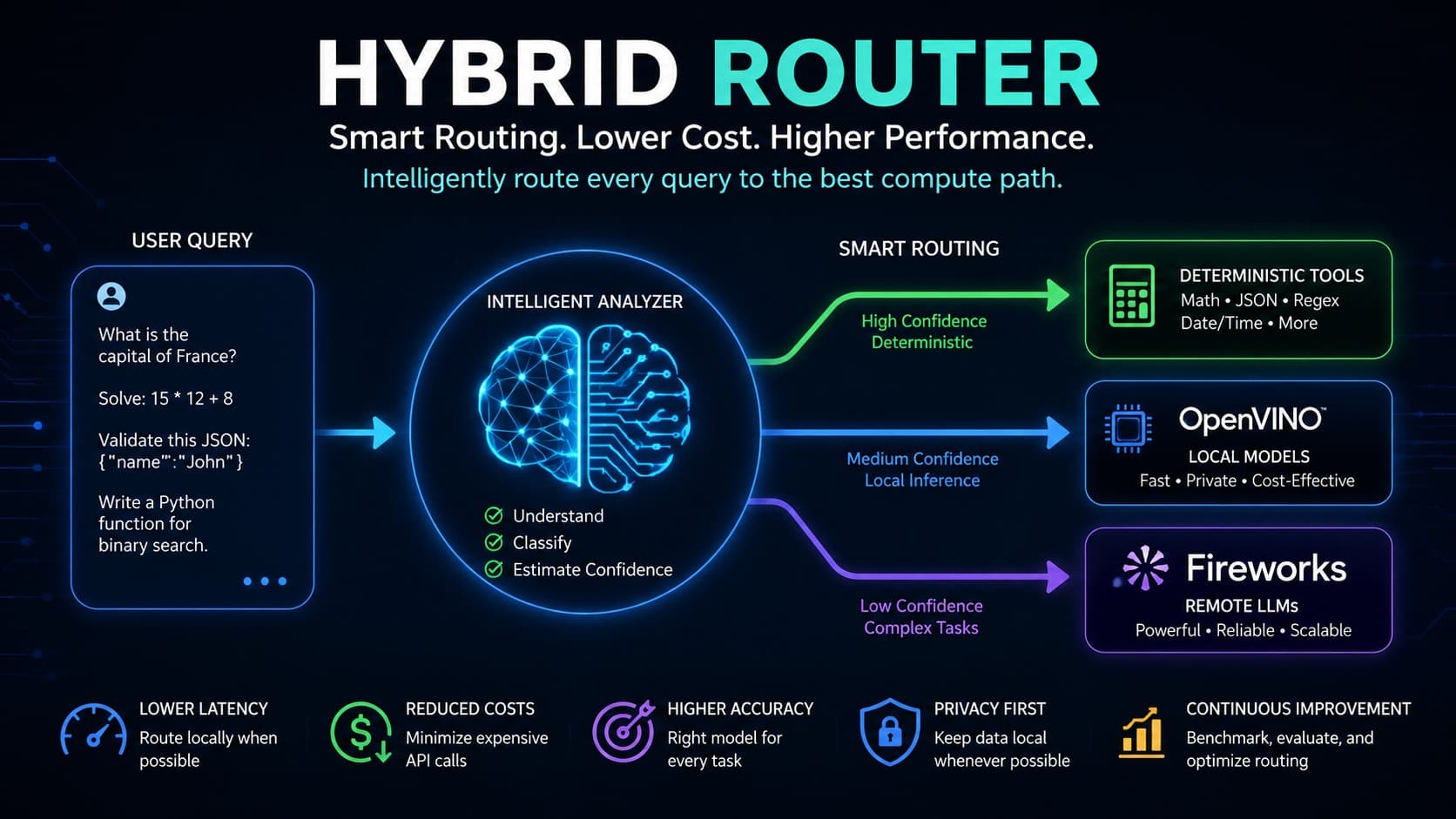
Hybrid Router is an intelligent AI inference system that dynamically selects the best execution path for each user query instead of relying on a single large language model. The system first analyzes the incoming prompt to identify the task type, estimate its complexity, and determine whether it can be solved deterministically or requires generative AI.
For structured tasks such as mathematical calculations, JSON validation, regular expression verification, and date/time operations, the router invokes specialized deterministic tools that produce fast, accurate, and reproducible results without consuming LLM tokens. For more complex natural language and coding tasks, the router attempts local inference using OpenVINO-optimized models running on Intel hardware, reducing latency and API costs. If the local model is unlikely to provide a sufficiently reliable answer or the task exceeds its capabilities, the system automatically falls back to Fireworks AI models for high-quality remote inference.
The routing decisions are driven by task classification, confidence estimation, and configurable thresholds, allowing the system to balance accuracy, response time, and operational cost. The architecture is modular, making it easy to add new tools, local models, or routing strategies in the future. The project also includes benchmarking and evaluation components that measure routing accuracy, latency, model utilization, and fallback frequency to continuously improve routing performance.
By combining deterministic tools, local inference, and cloud-based language models into a single adaptive pipeline, Hybrid Router delivers efficient, scalable, and cost-aware AI inference while maintaining high response quality across a wide range of tasks.