Top Builders
Explore the top contributors showcasing the highest number of app submissions within our community.
ExecuTorch
ExecuTorch is Meta's production-grade framework for on-device AI inference, allowing PyTorch models to run natively on mobile phones, wearables, embedded systems, and AI PCs without cloud connectivity. Unlike conversion-based pipelines, ExecuTorch exports models directly from torch.export to a .pte binary format, retaining PyTorch semantics through the entire deployment stack. It reached general availability (v1.0) in October 2025 and is already in production across Meta's Ray-Ban Smart Glasses, Meta Quest headsets, and billions of on-device AI feature interactions on Instagram, WhatsApp, and Messenger.
| General | |
|---|---|
| GA date | 18 Oct 2025 (v1.0) |
| Developer | Meta / PyTorch |
| Type | On-Device AI Inference Framework |
| License | BSD License |
| GitHub | pytorch/executorch |
| Documentation | docs.pytorch.org/executorch |
Core Features
- PyTorch-native export — models go from
torch.exportdirectly to.pteformat with no ONNX or TFLite conversion step. - 50 KB base runtime — minimal core footprint suitable for microcontrollers and embedded targets.
- Ahead-of-time compilation — models compiled offline to
.ptebinaries, reducing on-device startup overhead. - Single-line backend switching — swap hardware accelerators (CPU, NPU, GPU) without rewriting model code.
- Quantization tooling — INT8, INT4 (per-block), QAT+LoRA (QLoRA), and SpinQuant quantization via integrated PyTorch tools.
- Selective operator builds — include only operators the model uses, minimizing binary size.
- Multimodal support — composable backbone for LLMs, vision-language models, image segmentation, depth estimation, OCR, ASR, and object detection.
- Hugging Face Optimum-ExecuTorch — over 80% of the most-downloaded edge-friendly models on Hugging Face run on ExecuTorch out of the box.
Supported Hardware Backends
| Backend | Target | Status |
|---|---|---|
| XNNPACK + Arm KleidiAI | CPU (Android, iOS, Linux, AI PCs) | Stable |
| Apple Core ML | Apple silicon (iOS, macOS) | Stable |
| Qualcomm AI Engine / Hexagon NPU | Android (Qualcomm SoCs) | Stable |
| Arm Ethos-U NPU | Embedded / MCU | Stable |
| Vulkan GPU | Cross-platform GPU (Android, Linux) | Stable |
| Apple MPS (Metal Performance Shaders) | iOS / macOS GPU | Alpha |
| MediaTek NPU | Android (MediaTek SoCs) | Beta |
| Samsung Exynos NPU | Android (Samsung SoCs) | Alpha |
| Intel OpenVINO | AI PCs (Windows / Linux x86) | Alpha |
| CUDA | Linux / Windows GPU | Experimental |
Hardware partners include Apple, Arm, Cadence, Intel, MediaTek, NXP Semiconductors, Qualcomm, and Samsung.
Performance (Llama 3.2 1B Quantized)
| Device | Decode Speed | Prefill Speed |
|---|---|---|
| Samsung Galaxy S24+ | >40 tokens/s | >350 tokens/s |
| OnePlus 12 | 50.2 tokens/s | 260 tokens/s |
Quantization reduces model size by ~52% (2.3 GiB to 1.1 GiB) and peak runtime memory by ~39%, with 2.5x average decode latency improvement over BF16 baseline.
Tools and Resources
- GitHub — github.com/pytorch/executorch — source code, model export scripts, and backend integrations.
- Documentation — docs.pytorch.org/executorch/stable — installation, export workflow, and backend guides.
- PyPI —
pip install executorch— Python package for model export and tooling. - Llama export script —
export_llmcommand in the repo for exporting Llama variants to.pteformat. - PyTorch blog — pytorch.org/blog/introducing-executorch-1-0 — GA announcement with performance benchmarks.
Ecosystem and Integrations
- Powers on-device AI in Meta Ray-Ban Smart Glasses (live translation, visual captions, menu translation) and Oakley Meta Vanguard glasses (athletic performance insights).
- Runs scene understanding, depth estimation, hand tracking, and persistent room memory on Meta Quest 3 / Quest 3S.
- Llama 3.2 1B and 3B models were co-developed with Qualcomm and MediaTek for optimized Snapdragon deployment via ExecuTorch.
- Backend available in Hugging Face Optimum-ExecuTorch for direct integration with the Hugging Face model hub.
- Complements PyTorch Mobile for teams already in the PyTorch ecosystem, offering a significantly smaller runtime and better edge-hardware coverage.
Get started by cloning github.com/pytorch/executorch and following the quickstart guide, or install via pip install executorch for model export tooling.
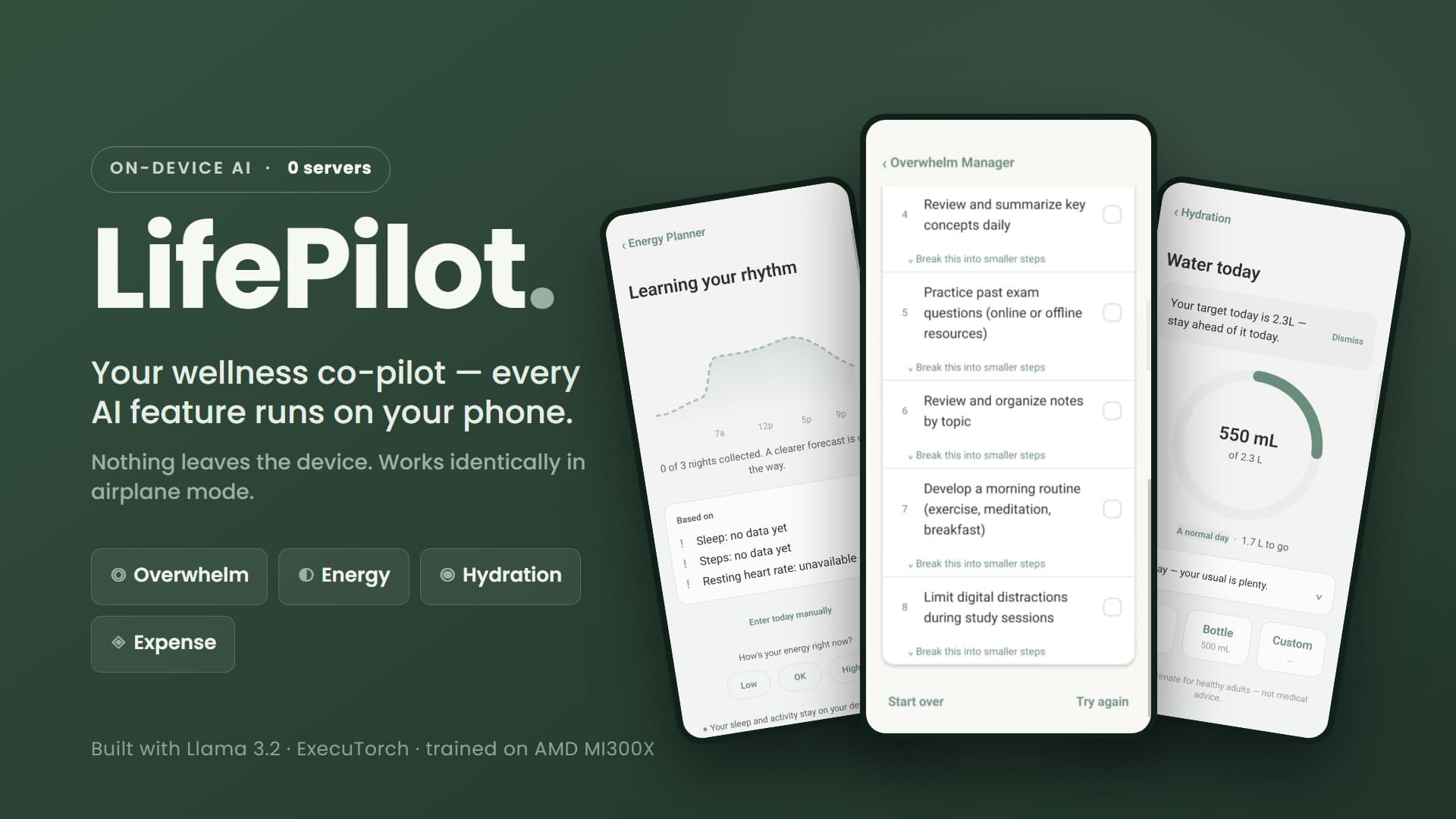
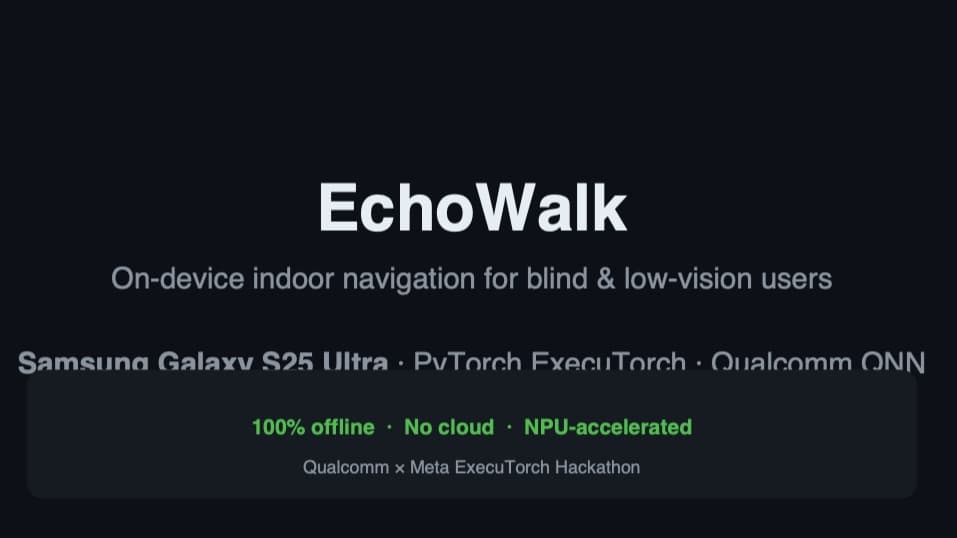
Meta Meta Executorch AI technology Hackathon projects
Discover innovative solutions crafted with Meta Meta Executorch AI technology, developed by our community members during our engaging hackathons.
.png&w=3840&q=75)
.png&w=3840&q=75)

.png&w=3840&q=75)