
Csaba Toth@tocsa
🤓 Latest Submissions

RAG Fusion with Cohere and Weaviate
RAG Fusion generates variations of the user's question under the hood. It retrieves matching documents for each variation and performs a fusion between them with re-ranking. A variation may match better into a small DB than the original question. First I used a synthetic data enrichment technique: since I already generated QnA for the Cohere Command fine tuning, with some extra scripts I processed that data further for ingestion into the Weaviate platform. This step involved LangChain and it's context aware Markdown chunker and I contributed back crucial features to a related open source project (https://github.com/CsabaConsulting/question_extractor ). I then worked out the details of the RAG Fusion, I used LangChain in some stages. 1. First I use the fine tuned Cohere Command model to generate variations of the user's question 2. I then retrieve matching documents for each variant and fuse them together with reciprical re-ranking 3. I then use the top K of the fused ranked list to augment two final queries. 3.1. One is a document mode co.chat request. 3.2. The other is a web connector mode co.chat request. In both cases I take advantage of co.chat's excellent conversation management feature. 4. Present the results in a highly customized and advanced (as far as Streamlit goes) UI. Citations are interpolated and referred. In the future I could improve on the UX, integrate it into ThruThink. Also I'll evaluate the results and possibly introduce PaLM2 harmful content protection.
18 Nov 2023
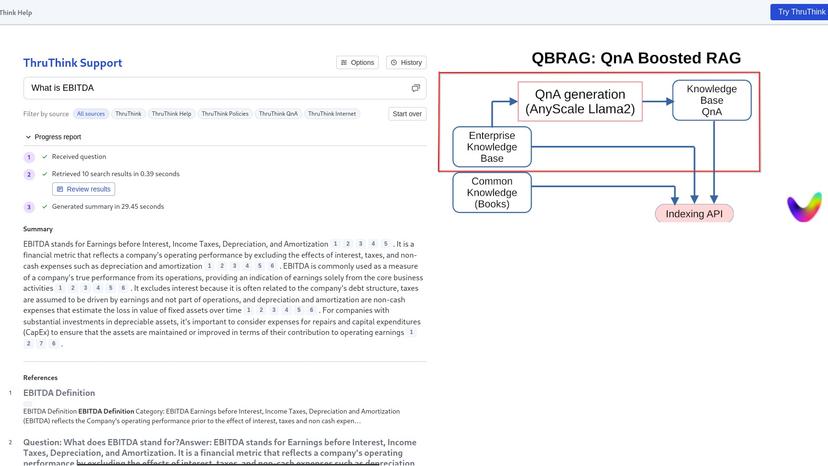
QnA Boosted RAG with Vectara
A company's knowledge bases often times don't answer the wide variety of questions a user could come up with. A Customer Support system ideally could answer specific (but wide variety) questions about the company's systems and knowledge (example: "How can I enter Cash Flow in ThruThink?"). But sometimes the user asks generic questions, such as "What is Cash Flow?" which could be sourced from the mind of a giant LLM model and / or the internet. My idea is to help and boost the performance by leveraging Question and Answer generation techniques - normally used for fine tuning but in this case - for knowledge base augmentation / indexing enrichment. The generated questions could support specific user queries potentially better matching than a "non focused" indexed generic knowledge base.
9 Nov 2023




