🤓 Latest Submissions
Visual Agents — Autonomous AI Computer Control
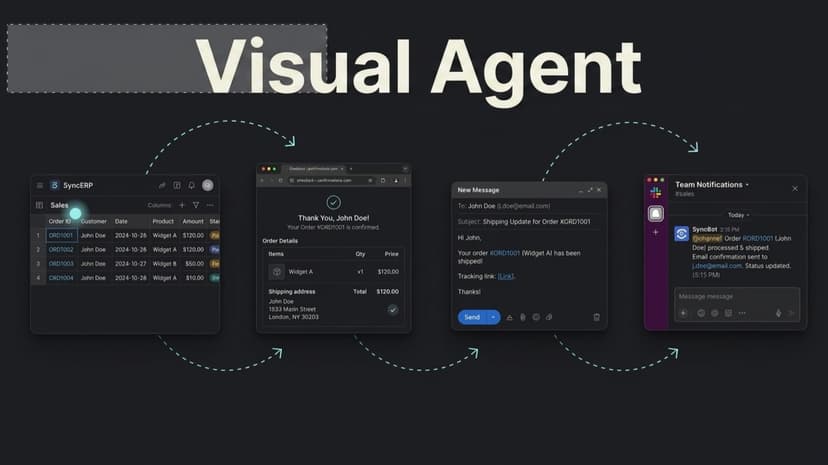
Visual Agents is an autonomous AI system that moves beyond chatbots into an agent that literally sees your screen, understands your intent, and completes complex tasks across ANY application on your OS, not just browsers. WHAT IT DOES Unlike browser-only or sandboxed tools like Comet or Claude Computer Use, Visual Agents operates across your entire operating system: Chrome, Excel, Photoshop, Slack, Terminal, SAP, desktop apps, internal enterprise tools, anything visible on screen. Give it a real-world instruction like "Pull last quarter's sales data from our ERP system, cross-reference it in Excel, build a summary chart, then email the final report via Outlook to the leadership team" and it plans every step, switches between apps, reads live UI state, handles errors mid-task, and delivers the result. No APIs. No plugins. No scripts. THE ARCHITECTURE: SEE, THINK, ACT, REMEMBER SEE: Gemini Live API streams real-time screen capture. OmniParser and SOM visual grounding identify interactive elements with pixel-level precision across any UI, any app, any OS state. THINK: A Task Planner powered by Gemini breaks goals into executable steps using state-aware planning (OSCAR-inspired), detecting failures and replanning autonomously without human input. ACT: The Action Executor performs clicks, typing, scrolling, app-switching, and keyboard shortcuts with post-action screenshot verification after every step. REMEMBER: A hierarchical memory system stores successful action trajectories. The agent gets smarter with every completed task. KEY HIGHLIGHTS Full OS control, not just browser automation V4 Mode: SOM grounding, trajectory memory, adaptive replanning, Gemini Live voice Real-Time Voice: Speak your task, no typing required Privacy-Aware: Never stores credentials or sensitive data TECH STACK Gemini Live API, Gemini 3 Pro, OmniParser, PyAutoGUI, MSS, PyAudio, Python 3.11 Open-source under MIT license. The age of manual computing is ending.
19 May 2026

Code2Paper for IBM Bob + DocSync MCP
Modern AI-assisted development is rapidly shifting toward coding agents and autonomous workflows, but current AI systems still suffer from a major structural limitation: their knowledge becomes outdated faster than the ecosystem evolves. During development, I repeatedly observed coding agents generating deprecated SDK integrations, obsolete model references, and outdated API patterns even after explicit instructions were provided. For example, when instructed to use the latest Gemini SDK patterns and models such as gemini-3.1-flash-lite, many coding assistants still reverted to older implementations like gemini-1.5 or deprecated SDK syntax. The issue was not reasoning capability — it was the static nature of LLM training data versus the rapidly evolving AI ecosystem. To solve this, I built DocSync MCP, a real-time documentation intelligence system for IBM Bob. DocSync continuously scrapes official SDK documentation, indexes it into a vector database, retrieves live implementation patterns, and exposes them through MCP tools directly inside Bob’s reasoning loop. Before generating SDK-specific code, Bob can search live docs, retrieve current APIs, and query live model catalogs from providers such as Google, OpenAI, and Anthropic. This grounds code generation on real-time ecosystem intelligence instead of outdated training memory. Alongside DocSync, I also built Code2Paper, a custom orchestration mode for IBM Bob that transforms a working research repository into a publication-ready research paper. Code2Paper analyzes repositories, identifies novelty, performs federated literature search, generates architecture diagrams, plots, and comparison tables, drafts sections using venue-specific Typst templates, and compiles complete papers for conferences such as NeurIPS, CVPR, and IEEE. Together, these systems solve two connected problems: keeping AI coding agents aligned with rapidly evolving technologies, and automating scientific communication directly from codebases.
17 May 2026



