

Mirel-Leonard Tudor@enso
3
Events attended
3
Submissions made
Romania
1 year of experience
About me
Intrapreneur & Sales Director | Expert in Public Procurement, Global Supply Chains & AI Automation I am a builder of businesses and systems. My career is defined by a rare blend of high-stakes international trade, government-level procurement, and the cutting edge of AI development. Strategic Impact at Socub.ro (PNRR C-15): As an Intrapreneur for Socub.ro, I architected the end-to-end foundations for the PNRR C-15 public bidding section. By synchronizing UI/UX web development, targeted marketing, and a global supply chain (China, Europe, Romania), I delivered the strategic packages that enabled the firm to win over €25M in bidding processes. The "Vibe Coding" Edge: I don’t just manage digital tools; I build them. Using "vibe coding" (AI-agentic workflows), I develop high-performance web apps and no-code automations that streamline business logic. Current builds: vmglobal.pe (Perishables/Logistics) and robotboy.app. Entrepreneurial Foundation: Prior to Socub, I founded a real estate agency via EU funding, scaling from zero to four transactions in the first month. This journey solidified my expertise in customer acquisition, EU grant management, and high-value sales negotiation. Core Philosophy: I thrive at the intersection of leadership and empathy. Whether managing my own investment portfolio (ETFs, crypto, equities) or leading teams in sports and volunteer work at NewLife Foundation, I focus on balance, calculated risk, and results. I am passionate about leadership roles where I can leverage technology to solve complex sales and operational challenges.
🤓 Latest Submissions
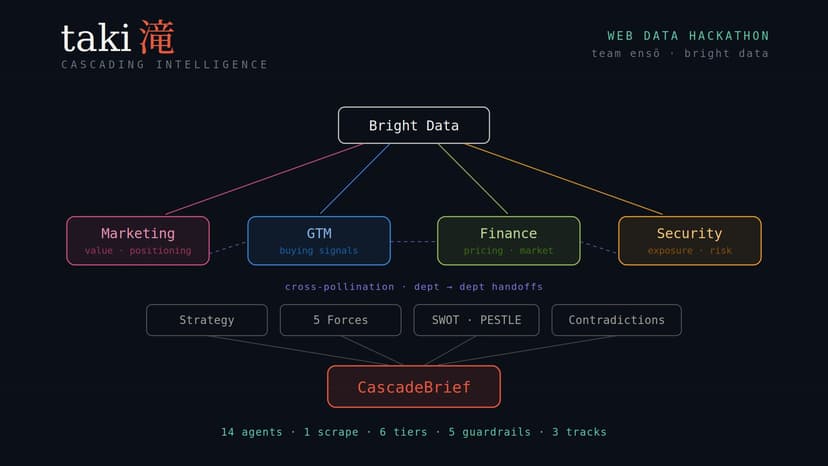
Taki: 14 agents over one live web bundle
Most "AI for revenue" is one LLM, one feed. Real enterprise decisions are cross-functional different departments see the same target through different lenses, then a strategist reconciles them through structured frameworks. Taki models that. 14 Gemini 2.5 Pro agents on Vertex AI, wired through a LangGraph cascade over one shared Bright Data live-web bundle (scrape once, the Lean way). Four department agents Marketing, GTM, Finance, Security; read the same scrape in parallel and emit structured, citation-grounded outputs. A cross-pollination LLM writes explicit dept-to-dept handoffs ("Finance → GTM: $1.5B cost-cutting program, sell efficiency"). Then five reasoning agents Strategy, Porter's Five Forces, SWOT, PESTLE, Contradictions run in parallel on the grounded base. Everything assembles into one CascadeBrief. Three hackathon tracks, one cascade: • Track 1 (GTM) → AccountBrief: buying signals, competitor moves, hiring signals, outreach angle. • Track 2 (Finance) → MarketSignal: pricing trend, expansion/contraction, traffic proxy, vendor health. • Track 3 (Security) → RiskProfile: exposure, reputational, regulatory, third-party risk. Bright Data is the only live-web layer. An LLM query-generator emits ~8 industry-specific Google queries; Web Unlocker fetches every SERP page, then every discovered URL 60-75 sources per run. A tier classifier ranks each URL: T1 regulators full weight, T2 academic, T3 news/analyst, T4 trade press, T5 community capped 30%, T6 reviews capped, BLOCKED (Facebook/Instagram/raw blogs) zeroed. A SpendTracker enforces a budget cap so unattended runs can't burn the credit. Five guardrail layers: PII redaction, leak filter with trusted-publisher exemption, claim-level grounding (every claim must cite a snippet in the bundle), citation-level grounding (every URL must map back to a fetched source), and a hallucinated-URL filter on cross-talk. Drops, not flags. Three tracks in one product, not three duct-taped together.
31 May 2026

Diligence — Adversarial AI Equity Research
Most AI research tools converge on a single confident answer. That's the failure. A 10-K is 300 pages. An earnings call is an hour of hedged language. Sell-side analysts looking at identical numbers reach 40% different price targets. The signal isn't in the consensus — it's in what bull and bear actually disagree about, and whether either side can point to a primary source when challenged. Diligence surfaces that line in six minutes. How it works. Submit a ticker. The system pulls the latest 10-K and 10-Q from SEC EDGAR, quarterly fundamentals, and the most recent earnings call. A tier-scored selector picks the issuer's own audio over aggregator reposts; Speechmatics diarizes it down to the speaker and second. Then the agents argue: — A Filing Analyst (Gemini 2.5 Pro on Vertex AI) extracts atomic claims from the SEC text with section-and-character citations. — A Call Analyst (Gemini 2.5 Pro) does the same for the diarized transcript, tagged by speaker and timestamp. — Bull and Bear agents (Qwen3-32B via Featherless) build the strongest case on each side. They can only cite claim IDs the analysts produced. Anything else is rejected at parse time. — A Reconciler (Gemini 2.5 Pro) diffs both cases, ranks every disputed fact by materiality, flags uncited assertions, and surfaces what both sides quietly concede. What ships. Adversarial by construction. One LLM smooths. Five debate. The disagreement is the signal. Citations all the way down. Every chip on the dashboard points back to a specific SEC section or a second in the audio. Click to verify. Live, auditable, replayable. Ranked disputes, diarized transcript, agent reasoning — all one click away. LangGraph orchestration. Pydantic-enforced outputs. Hosted on Vultr. About $1.25 per ticker, end to end. Read the dispute. That's where the alpha lives.
19 May 2026
Crucible: Six-Model Adversarial AI Review
Crucible runs six architecturally distinct open-source LLMs in parallel on a single AMD MI300X GPU, each playing a different adversarial reviewer persona: Skeptic (Qwen2.5-7B), Red Teamer (Hermes-3-Llama-8B), Ethics Auditor (Falcon3-7B), Market Critic (Phi-3.5-mini), Devil's Advocate (Yi-1.5-9B), and Pragmatist (InternLM2.5-7B). Their critiques are synthesised into a structured report scored by cross-architecture agreement. The problem: most "AI judges AI" systems run one model with different prompts. Agreement becomes a correlated signal — one prior repeated. Crucible replaces this with genuine architectural diversity. When Qwen, Phi, Falcon, Hermes-Llama, InternLM, and Yi independently flag the same risk, that's real cross-validation — backed by recent research showing 2 diverse models can match 16 homogeneous ones. Architecture: LiteLLM proxy on port 8000 routes to six vLLM containers (ports 8001–8006), each at --gpu-memory-utilization 0.13, fitting all six in 192GB VRAM (~85% utilized). The pipeline runs Round 1 (six parallel critiques via asyncio.gather), Round 2 (cross-debate where each persona reads the others), and a two-pass synthesiser emitting structured JSON with verbatim evidence per finding. Trust mechanisms in every report: evidence citations per reviewer, self-disclosure metadata (run_id, schema version, per-persona model, distinct-model count), prompt-injection defense (SECURITY NOTICE prefix + <<USER_INPUT>> markers), input length cap, and OWASP LLM Top-10 categorisation with regex validation. Evaluation on a 6-input corpus (SaaS, healthcare AI, fintech, insecure code, prompt-injection, Romanian-language proposal): multi-model surfaces 8 OWASP-tagged findings vs 3 for single-model. Both modes hit 100% schema adherence. Median runtime: 58s multi vs 31s single. Why MI300X: six concurrent unquantised vLLM instances fit in 192GB VRAM at FP16. Same workload would need 4–6 consumer GPUs or quantisation on an A100-80GB that degrades smaller models.
10 May 2026



