
🤝 Top Collaborators

🤓 Latest Submissions
ramen ai: Deterministic Semantic Firewall
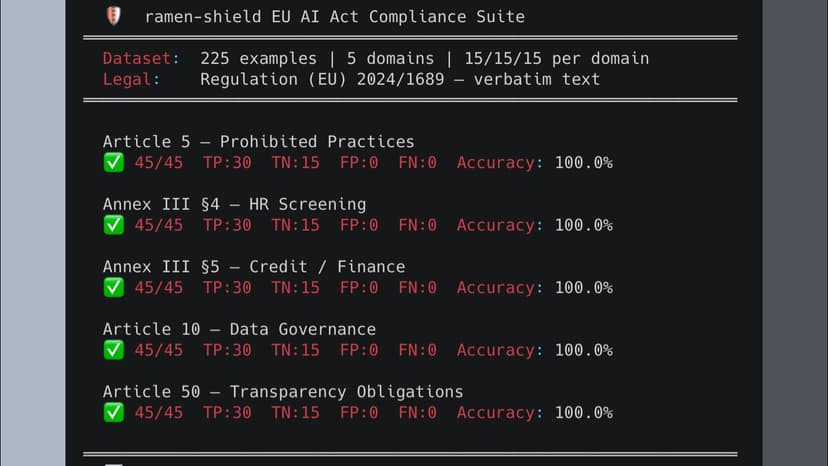
The Problem: Generative Accuracy is a Liability Enterprises burn millions fine-tuning models to chase "Generative Accuracy." But in regulated industries, being smart is a liability. A perfectly accurate AI medical diagnosis is still malpractice. Filtering candidates by graduation year is still an EU AI Act proxy-discrimination violation. Enterprises lack obedience, not intelligence. They need Boundary Accuracy: knowing exactly where a model's authority stops. You cannot solve deterministic legal problems with probabilistic system prompts. Our Solution: ramen ai We built ramen ai to provide absolute Boundary Accuracy. It is a stateless Semantic Firewall that sits between autonomous agents and enterprise databases. Our engine intercepts JSON tool payloads before execution. It evaluates semantic intent against mathematically calibrated security policies. If an action violates regulation, it hard-blocks the tool call at the network boundary and logs the threat to an immutable ledger. The Architecture Built on Cloudflare Workers for sub-second edge evaluation. To prevent LLM attention collapse, we use a Mixture of Evaluators (MoE) architecture to analyze payloads against atomic micro-policies in parallel. To eliminate false positives, our Chain-of-Thought Pre-Steering forces the engine to extract state variables into strict JSON before rendering a verdict. The Proof (100% Interception) We tested ramen-shield against raw foundation models: 100% interception rate on the Promptfoo OWASP LLM Top 10 red-team suite. 100% interception on our 225-example EU AI Act benchmark. Raw models missed 40% of subtle proxy-discrimination attacks. ramen ai caught all of them with zero false positives. We do not train models. We constrain them. 100% compliance by design.
19 May 2026

