.png&w=256&q=75)
Aksh Desai@akshcilans60743
2
Events attended
2
Submissions made
India
1 year of experience
Socials
🤝 Top Collaborators
.png&w=640&q=75)
.png&w=640&q=75)
.png&w=640&q=75)
.png&w=640&q=75)
🤓 Latest Submissions
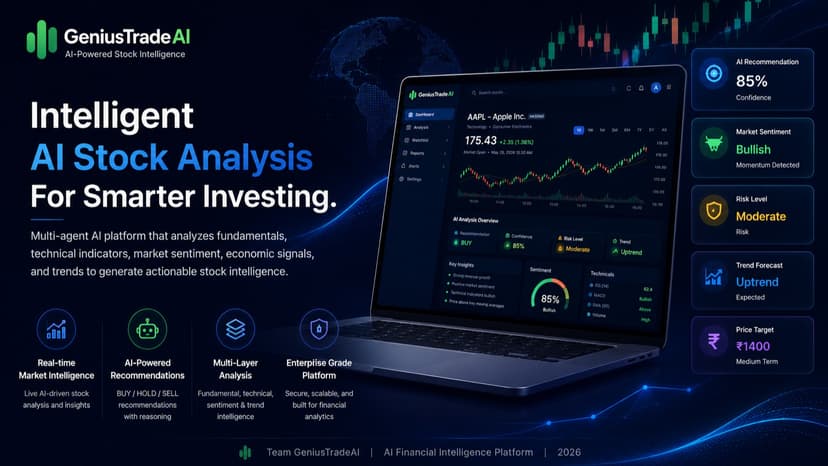
GeniusTrade AI
GeniusTrade AI is a multi-agent AI trading intelligence platform that transforms live web data into real-time market analysis and actionable trading decisions. Built for modern retail and institutional traders, the platform eliminates the need for hours of manual research by automatically collecting, analysing, and interpreting financial information from across the web. The system continuously gathers live market data, including price movements, technical indicators, financial news, macroeconomic updates, sentiment signals, and trading activity from real-time web sources. Instead of presenting raw charts and fragmented information, GeniusTrade AI orchestrates multiple specialised AI agents that work together to generate structured, explainable, and decision-ready market intelligence. Powered by LangGraph, the platform uses a coordinated multi-agent architecture where dedicated AI analysts independently evaluate different aspects of the market, including fundamentals, technical analysis, sentiment, price action, trend strength, and economic conditions. A final trader agent synthesises these insights, resolves conflicting signals, evaluates confidence levels and risk exposure, and delivers a unified trading recommendation with clear reasoning. GeniusTrade AI provides traders with institutional-grade intelligence through an intuitive interface, enabling users to understand market behavior, identify opportunities, and react faster to changing conditions. With real-time web access, explainable AI reasoning, live sentiment tracking, and automated analytical workflows, the platform serves as an always-on AI analyst team, delivering continuously updated trading insights on demand. GeniusTrade AI combines live web intelligence, autonomous AI agents, predictive analytics, and explainable recommendations to help traders interact with financial markets more intelligently, quickly, transparently, and data-driven.
31 May 2026

Preserving Heritage with AI-Driven PDF Restoration
Across libraries, temples, research institutions, trusts, and private collections worldwide, millions of valuable books, manuscripts, journals, and archival documents exist only in degraded PDF or scanned formats. These documents often suffer from yellowed pages, faded text, stains, stamps, handwritten markings, shadows, skewed scans, low resolution, blank pages, and inconsistent formatting, making them difficult to read, preserve, search, or distribute digitally. Despite the growing importance of digital preservation and AI-driven knowledge accessibility, there is currently no scalable and user-friendly platform specifically designed to transform poor-quality archival PDFs into clean, digitally optimized documents while preserving their authenticity. This project aims to build an advanced AI-powered web platform that automatically converts old, damaged, stamped, noisy, or low-quality PDF documents into clean, publication-ready digital PDFs. The platform will enhance readability, remove unwanted artifacts, eliminate blank pages, correct orientation and alignment issues, improve contrast and sharpness, and optionally remove institutional stamps through AI-assisted or manual review workflows. Beyond PDF cleanup, the vision is to create a digital restoration ecosystem that empowers libraries, scholars, publishers, spiritual organizations, and archival institutions to modernize valuable knowledge into accessible, searchable, and professionally presentable digital assets. The proposed system will combine image processing, OCR enhancement, AI-based document restoration, and intuitive web workflows to make large-scale digitization practical, affordable, and accurate. Ultimately, this initiative seeks to bridge the gap between historical knowledge preservation and modern digital accessibility, ensuring that invaluable cultural and intellectual heritage can be preserved and utilized for future generations.
10 May 2026

