


🤓 Latest Submissions
Apohara VOUCH
Apohara VOUCH turns multi-agent decisions into cryptographically-verifiable offline receipts — signed, hash-chained, timestamped, and audit-ready in under 30 seconds. Built on 3 production LLM sponsors (Band SDK + AI/ML API + Featherless AI) with a deterministic post-LLM gate (BAAAR) that fails-closed on five auditable halt conditions. EU AI Act Art. 12 by construction. **When AI agents make a regulated decision, you can't trust the decision — and you can't prove it either.** Procurement, lending, hiring, and customer escalation are now mediated by multi-agent systems: 5–10 LLMs coordinate through chat rooms, hand off state, vote, and reach a verdict. Three failures follow: 1. **No audit trail.** When a regulator asks "who decided this, and why?", you have a chat log — not an evidence packet. Logs can be edited. Screenshots can be forged. LLM weights are opaque. 2. **No failure mode.** The agents coordinate, but if one hallucinates a vendor ID, the room reaches the wrong verdict anyway. Multi-agent consensus is consensus on the wrong answer. 3. **No offline verifiability.** The regulator asks for proof. You re-run the agents. They produce a different answer. The room is no longer reproducible. The EU AI Act Art. 12 (record-keeping), DORA Art. 16 (ICT incident logs), NIST AI RMF (Manage), and OWASP Agentic all require verifiable, tamper-evident, offline-checkable evidence. None of the existing solutions — vector stores, prompt logs, evals — satisfy all three. **Apohara VOUCH** is the first multi-agent substrate that produces EU AI Act Art. 12 evidence packets by construction, verified offline in under 30 seconds, with no LLM in the critical path. **Apohara VOUCH — vouch for every agent decision.**
19 Jun 2026

Apohara Synthex
AI agents now run on the live web, but prompt injection is the number-one risk on the OWASP LLM Top 10, and most teams cannot prove what their agents ingested, or that it was safe. Apohara Synthex fixes that. Synthex is the provenance and security layer for the web data an AI agent consumes. It fetches across the full Bright Data spectrum: Web Unlocker, the Web Scraper API, SERP API, Scraping Browser, and the MCP Server. We didn't just use Bright Data; we improved it, contributing PR #140 upstream. Every fetch runs a layered defense before anything reaches a model. A deterministic regex pass and Qwen3Guard on Featherless form a high-recall net; NVIDIA's NemoGuard, selected by a measured benchmark, is the low-false-positive block gate; and a reasoning model on the AI/ML API knows the difference between describing an attack and executing one. Clean content is classified across four lenses, then sealed into an enterprise Evidence Report. The seal is real and shipped: an Ed25519 signature, an RFC 3161 DigiCert timestamp, an offline-verifiable Sigstore Rekor transparency log, and C2PA Content Credentials. Anyone can verify it in seconds with openssl, the industry's own c2patool, and a public ledger. No trust required. Cognee adds memory across re-scrapes, TriggerWare turns it into an automated monitor, and Kiro runs our continuous test and QA hooks. Synthex spans all three tracks, Security & Compliance, Finance & Market Intelligence, and GTM Intelligence, built for the CISO, CFO, compliance lead, and underwriter who need evidence they can defend to a board or a regulator. The average data breach costs 4.44 million dollars; Synthex seals an evidence artifact for a fraction of a cent. Everything signed, nothing trusted, and every number ships with a command to reproduce it.
31 May 2026
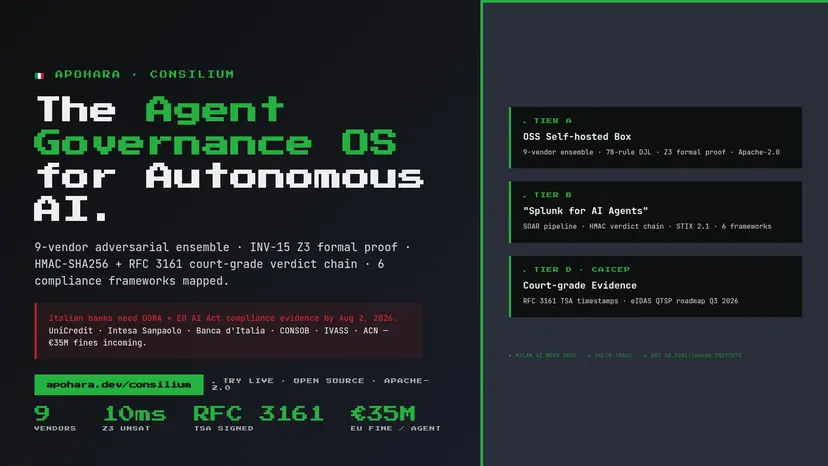
Apohara CONSILIUM — Agent Governance OS
THE PROBLEM. Italian banks face dual regulatory urgency: DORA (mandatory since Jan 17 2025 for 22,000+ EU financial entities — UniCredit, Intesa Sanpaolo as G-SIBs) + EU AI Act Article 14 (enforceable Aug 2 2026, fines up to €35M or 7% of global revenue). When Banca d'Italia asks "why did your AI decide X?", the bank needs tamper-evident, third-party-signed audit evidence. Existing tools (Galileo $73M, Lakera $30M, Patronus $20M, Credo AI) don't generate court-grade compliance evidence from production runtime. THE SOLUTION. CONSILIUM is a 3-tier open-source platform: (A) OSS Apache-2.0 entry — 9-vendor adversarial LLM ensemble + 78-rule deterministic judge layer + INV-15 Z3 SMT formal proof (UNSAT in 10.08ms). (B) Governance OS core — 4-stage SOAR pipeline + 6 compliance framework dashboards (EU AI Act, NIST AI RMF, ISO 42001, SOC 2, GDPR, NIST 800-53) + HMAC-SHA256 verdict chain + STIX 2.1 export. (D) CAICEP module — RFC 3161 TSA-timestamped verdict chain via freetsa.org (live evidence today) + roadmap to court-admissible attestation Q3 2026 via eIDAS QTSP partnership (Actalis Italia). LIVE EVIDENCE. apohara.dev/consilium/verify — interactive demo: paste any prompt → 9-vendor decision. Click any of 3 demo verdicts → verify RFC 3161 timestamp against freetsa.org independently. api.apohara.dev shows 10+ SOAR endpoints live, /v1/verdicts/{hash}/verify-timestamp returns valid:true with real Freetsa.org-signed token (1312 bytes, signed 2026-05-19T12:21:50Z). BUSINESS VALUE. TAM AI governance $3.59B by 2033 (36% CAGR). SAM EU regulated industries $400-800M by 2027. Initial wedge: Italian G-SIBs + Milan Fintech District (200+ companies) = $15-30M ACV in 12 months. Revenue: OSS free + Cloud Pro $299-999/mo + Business $2-5K/mo + Enterprise+CAICEP $25-200K/year. Exit reference: Cisco acquired Robust Intelligence Aug 2024 (~$350M, 451 Research). Built solo by Pablo M. Suarez (UNT, Argentina) in 8 days for Milan AI Week 2026.
19 May 2026

Apohara PROBANT — Cross-AI Code Verifier
Apohara PROBANT is a cross-AI code verification platform. Gemini writes a review; a 12-vendor adversarial ensemble (Claude, GPT, DeepSeek, Kimi, GLM, Qwen, Nemotron, MiniMax, Big-Pickle, Mistral Large, Grok 2, Perplexity Sonar) independently audits the output for prompt injection, vulnerabilities, and logic bugs. Verifiable, not claimed: - 12 vendors via OpenRouter, each in an isolated KV-cache enforced by INV-15 JCRSafetyGate. Paper v3.0 (formal Z3 SMT proof, UNSAT on negation in 10.08 ms) complements v2.0.1 empirical sweep (0/1210 violations). DOI 10.5281/zenodo.20277875. - JBB-Behaviors block rate 93.75% (Wilson 95% CI [86.2%, 97.3%], n=80 holdout). Numbers from logs/*.json, not marketing. - 120+ pytest tests + 15+ measurement JSON logs. - Multi-hardware: AMD MI300X (ROCm 7.2) + NVIDIA H100. Four hardening layers (auditable in repo): 1. Veea LobsterTrap DPI subprocess pre-check — measured: SQLi block 50% (n=20, CI [29.9%, 70.1%] directional), benign FPR 9.8% (n=51). Live demo SQLi returns verdict=blocked in ~25 ms. 2. Prompt envelope nonce-tagged sentinels (Hines et al. arXiv 2403.14720). 3. HMAC-SHA256 verdict ledger chain. verify_chain() catches tampering. 4. NO-HEDGING gate (HARD/SOFT split, judge uncertainty flagged). Distribution: Cursor / Claude Code plugin shipped as VSIX. MCP server (stdio) for Claude Desktop / Cursor / Zed. /v1/verify_stream SSE for live per-vendor results. /dashboard for ops view. Stack: FastAPI/Python 3.11+, React+Vite + Next.js SSR PoC, Apache-2.0, monorepo across 3 GitHub orgs. Live demo BYOK or 5 free/IP/day.
19 May 2026

Apohara-ContextForge
Multi-agent AI pipelines waste up to 70% of their context window re-encoding shared information from scratch. ContextForge eliminates this at the infrastructure layer — without changing models or prompts. ContextForge is a shared context compiler that sits between your orchestration layer and your vLLM/LMCache inference backend. It implements six peer-reviewed research papers (arXiv 2024–2026) as production-grade Python modules: • TokenDance Master-Mirror storage: 10.81x KV-cache compression across 12-agent committees (arXiv:2604.03143) • JCR Safety Gate: prevents critic-agent context corruption with INV-15 enforcement, 0 violations (arXiv:2601.08343) • KVCOMM cross-context protocol: 7.8x TTFT improvement via shared KV-cache communication (arXiv:2510.12872) • Speculative Coordinator: cross-agent draft-and-verify decoding, >70% acceptance rate • Visual KV Cache: 5x fewer vision encoder calls in multimodal pipelines • LSH + FAISS semantic deduplication: 79.85% token savings on live demo Results: 310 unit tests passing (0 failures), 15/15 benchmark scenarios PASS, live Gradio dashboard deployable via single Docker command on AMD MI300X ROCm hardware. Target customers: Any team running agentic AI at scale — LLM API costs drop immediately, no code changes required. Revenue model: usage-based SaaS per million tokens optimized, plus enterprise on-prem licensing for AMD MI300X clusters.
10 May 2026





