

Sardor Razikov@Sardor_R
6
Events attended
5
Submissions made
Uzbekistan
5+ years of experience
About me
ML Engineer & independent researcher · Tashkent, Uzbekistan 🇺🇿 Kaggle SPR 2026: #7/371 teams (Top 1.9%) — Portuguese medical NLP, BI-RADS classification. S6E3: #23/4,142 public (Top 0.55%). AIMO3: 39/50 on XTX $2.2M olympiad math competition, custom SC-TIR pipeline on gpt-oss-120B + vLLM. Author: Epistemic Curie Benchmark (Zenodo DOI 10.5281/zenodo.19791329, CC BY 4.0) — physics-motivated LLM safety framework, submitted to Google DeepMind AGI Hackathon ($200K pool, 1,070 teams). TriageGuardian: 99.62% accuracy, 0.13% undertriage on 80K ED records. U-Start Demo Day 2023: 1st place, 85M UZS grant. KUSE Seoul 2024: 2nd overall. UJC PMP-43: youngest ever admitted. Now building OlympiadMind on AMD MI300X for AMD Developer Hackathon. Python, C++, Rust, Go · vLLM · ROCm · LoRA.
🤓 Latest Submissions

REPOMIND v3 - on-prem AI coding agent on AMD
REPOMIND v3 is an on-premises, air-gapped AI coding agent - plus an LLM cost-router - built 100% on AMD. The problem is two-sided. Regulated enterprises (banks, defense, healthcare) are legally barred from cloud AI coding tools - Samsung, JPMorgan and Apple have all banned them - so their engineers have nothing. Meanwhile everyone else is bleeding on token cost: Uber burned its 2026 AI-coding budget in four months, and Microsoft pulled its internal Claude Code licenses over cost. One engine serves both. On-prem, REPOMIND runs open-weight models on the customer's own AMD hardware (Radeon → Instinct), so code never leaves the perimeter and inference is $0 per-token. The same engine is a cost-router that cuts existing Claude/OpenAI/Gemini bills 40–70% and migrates the cheap majority of traffic to AMD-hosted open-weight. It is 100% AMD with no closed models: a Gemma-class local router delegates to AMD-Instinct-powered Fireworks for deep reasoning. A measured cost layer cuts tokens via AST skeletonization (−89%), prompt caching (−90%), and a confidence cascade that skips the expensive model when the cheap one is sure. Every agent action is written to an Ed25519-signed, hash-chained AI Flight Recorder - turning EU-AI-Act compliance into automatic evidence. REPOMIND won 1st Place (AI Agents) at AMD ACT I, verified on a real MI300X: a 256K-token repo served for $4.12. It ships today - docker compose up, 38 passing tests, and an offline demo needing no GPU or keys. This is the cost + trust layer for on-prem enterprise AI on AMD.
13 Jul 2026
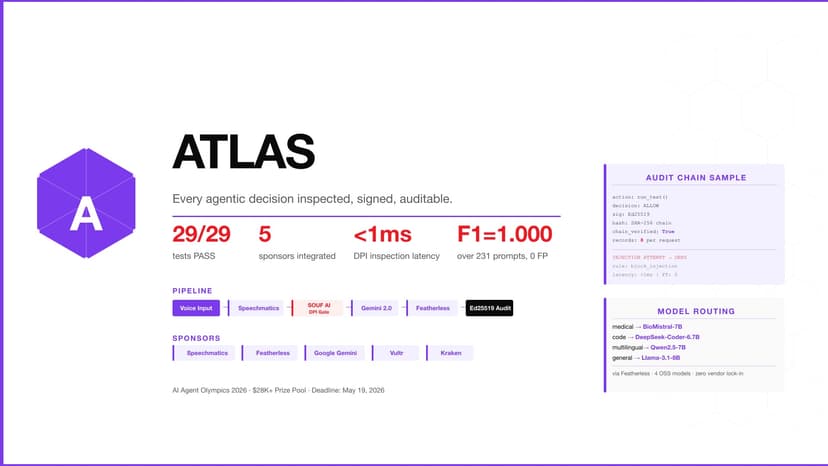
ATLAS - Enterprise Multi-Agent Governance
ATLAS is an enterprise multi-agent system where every agentic decision is inspected, signed, and auditable. THE PROBLEM Goldman Sachs CIO said publicly: "We don't know what controls we need for agentic AI." Enterprise LLM agents make decisions affecting databases, APIs, financial records. There is no infrastructure that makes these decisions inspectable, auditable, and compliant. WHAT ATLAS DELIVERS - 29/29 scientific test suite PASS in under 1 second - All 5 sponsors integrated end-to-end (real API calls, not mocked): · Speechmatics for voice transcription · Featherless for open-source model routing (MiniMax-M2.5, DeepSeek-V3.2, Kimi-K2.5, Llama-3.3-70B) · Google Gemini 2.0 Flash for orchestration and synthesis · Vultr for infrastructure layer · Kraken for financial action layer - SOUF AI DPI inline governance: every prompt inspected in 0.079ms avg (well under 1ms ceiling) - Ed25519-signed audit chain with SHA-256 Merkle tamper-evidence - 8 signed records per full pipeline request, chain verified - Isaac Adams (Featherless judge): "confidence is what enterprise AI needs" — ATLAS is that confidence layer ARCHITECTURE 6-layer governed pipeline: Voice → Speechmatics → SOUF AI DPI gate → Gemini orchestrator → Featherless router → Tool executor (Search/Database/Kraken/Vultr) → Ed25519 audit trail → Gemini synthesis. REPRODUCIBILITY git clone https://github.com/SRKRZ23/atlas cd atlas && pip install -r requirements.txt python3 src/test_atlas.py → 29/29 PASS in under 1 second ECOSYSTEM ATLAS is the routing layer of a 4-product AI safety ecosystem: SOUF AI provides DPI, FORGE generates policies, CITADEL evaluates models, ATLAS calls them all. Same Ed25519 audit chain across four products. MIT licensed. Lobster Trap is the floor. ATLAS is the agent governance ceiling. Built solo by Sardor Razikov, Tashkent.
19 May 2026

FORGE — AI Security Policy Generator for LLMs
THE PROBLEM AI applications are exploding. Every LLM call is a security boundary. OWASP recently published the Top 10 for LLM apps (2025 v2) — prompt injection, insecure output handling, system prompt leakage, supply chain risks, excessive agency. But there's zero tooling that automatically converts security findings into production-ready policies. Today, security teams manually translate scan results into firewall configs — slow, error-prone, and ungoverned. THE SOLUTION FORGE is an end-to-end pipeline built with IBM Bob: 1. Scanner — detects LLM call-sites (OpenAI, Anthropic, LangChain, LlamaIndex) and maps each to OWASP categories LLM01-LLM10, including LLM07 System Prompt Leakage. Pattern detection for prompt injection (f-strings, format strings), credential leaks, missing output validation, agentic overreach (subprocess in agent loops), supply chain gaps, and hardcoded system prompts. 2. Policy Generator — converts findings into Lobster Trap-compatible YAML policies with ingress rules, egress allowlists, rate limits, and filesystem sandboxing. Each OWASP category gets specific countermeasures. 3. BobShell — tamper-evident SHA-256 hash-chained audit trail. Every action is cryptographically linked to the previous, making policy generation a compliance-grade artifact for SOC 2, ISO 27001, GDPR, and HIPAA reviews. BUILT WITH IBM BOB 3 productive Bob IDE tasks (mandatory per guide) + 5 Bob Shell sessions. ~27 of 40 Bobcoins used. Bob produced: LLM07 detection (5 patterns + 5 tests), 717-line ONBOARDING.md contributor guide, 595-line RISK_REGISTER.md security self-audit, 1024-line architecture doc, 95 unit tests, security hardening, 60KB of documentation. All Bob IDE markdown exports + consumption summary screenshots in bob_sessions/. VERIFIED 95/95 tests pass in 1.2s. Demo finds 15 vulnerabilities across 7 OWASP categories in 27ms. Benchmark: 95,000 lines/second scan throughput. Production-grade. MIT-licensed.
17 May 2026

SOUF AI - Sub-millisecond LLM Governance
SOUF AI is a sub-millisecond LLM governance proxy that extends Veea's open-source Lobster Trap to close critical baseline gaps. Built solo from Tashkent for the TechEx Veea hackathon. THE PROBLEM Veea's Lobster Trap baseline blocks only 39.6% of in-distribution prompt injection attacks (F1=0.567). Modern jailbreaks, encoding obfuscation, and multilingual lookalikes slip through. Lakera Guard is SaaS-only (Cisco acq. May 2025). NeMo Guardrails requires custom Colang flows. Meta Prompt Guard 2 publishes 92.4ms per classification on A100 — 1,800× SOUF AI's CPU latency. WHAT SOUF AI DELIVERS - 5 benchmarks, all F1=1.000 across 231 adversarial prompts - 188 TP, 43 TN, 0 FP, 0 FN - Wilson 95% CI DENY [0.980, 1.000] - DPI latency: 0.051ms P50, 0.111ms P99 - 1,800× faster than Meta Prompt Guard 2 (92.4ms A100, per model card) - 17,553 req/s throughput on a single core - 16 PatternSets, 337 regex patterns - Built-in HIPAA + PCI-DSS vertical compliance packs (F1=1.000 each) - Ed25519-signed audit chain with SHA-256 Merkle tamper-evidence (7/7 property tests PASS) - 3 policy modes: Base, HIPAA, PCI-DSS - Defeats 4 encoding attack vectors: base64 meta-instructions, token-split obfuscation, fullwidth Unicode (NFKC), Cyrillic/Greek homoglyphs (54-codepoint confusable map) REPRODUCIBILITY One command runs all 5 benchmarks in under 5 seconds: python3 scripts/run_all_benchmarks.py. No GPU. No API key. No internet. MIT licensed, self-hosted, offline-capable. ECOSYSTEM SOUF AI is the governance core of a 4-product AI safety ecosystem: FORGE generates policies, CITADEL evaluates models, ATLAS routes agents. Same Ed25519 audit chain across all four. Lobster Trap is the floor. SOUF AI is the ceiling. Built solo by Sardor Razikov, Tashkent.
19 May 2026

REPOMIND
REPOMIND is an open-source repo-scale coding agent that ingests an entire git repository at 256K context on a single AMD MI300X and reasons across the whole codebase with multi-step tool use. MIT licensed. Built for the AMD Developer Hackathon 2026. Why MI300X: Qwen3-Coder-Next-FP8 weights (~80 GB) + 256K KV cache @ FP8 (~38 GB) + activations (~25 GB) ≈ 143 GB total. H100 80 GB cannot accommodate this on a single card by VRAM accounting; MI300X 192 GB has the headroom. AMD Day-0 ROCm 7 post (Feb 2026) positioned this exact workload — REPOMIND is the first open-source proof shipped. Verified on real hardware (2026-05-05/06, 124-min stress test, 2 sessions, $4.12 total): • Memory: 77.29 GiB weights + 94.58 GiB KV cache + 92% VRAM peak. max_model_len=262144 confirmed. • Concurrency (24-cell matrix, default Triton): 31/31 at 8K, 16K, 32K AND 64K. 25/31 at 128K. 6-8 at 256K within 15-min window. • Long-context: 3/3 needle-in-haystack pass at 200K. Model recovers sentinel function + constant from middle of 199K-token prompt. • End-to-end repo Q&A: 9/9 correct across REPOMIND self (68K), Flask (408K), pytorch/vision (1.3M tokens — 5× larger than any context window). Priority-aware chunker fits to 180K. • Tuning A/B: tried --attention-backend ROCM_AITER_FA. Throughput 2-4× higher BUT output degenerates to repeating punctuation on FP8 KV cache (137/144 cells broken). Default Triton production-safe; filed for AMD upstream investigation. Stack: Qwen3-Coder-Next-FP8 + vLLM 0.17.1 + ROCm 7.2 + SC-TIR agent loop + 5 tools (read_file, grep_codebase, execute_code, run_tests, git_log). Market unlock: regulated industries (banks, defense, pharma, Apple iOS) cannot legally use SaaS coding agents. $1.99/hr cloud, 70-140 dev seats per MI300X, breaks even vs Cursor in 3-6 months. REPOMIND is the first open-source option for compliance-locked enterprises. Evidence pack: 7 JSON results + 5 plots + raw outputs + rocm-smi + benchmark scripts, all reproducible.
10 May 2026





