Mastering Multilingual Translations with LLaMA 3.1
Mastering Multilingual Translations with LLaMA 3.1
Language is the bridge that connects cultures, but translating between languages is far from straightforward. It's a nuanced art that goes beyond merely substituting words. Enter LLaMA 3.1, a powerful tool that's reshaping how we approach multilingual translations.
As an AI engineer, I've had the opportunity to work with various language models. LLaMA 3.1 stands out for its remarkable ability to grasp context and adapt translations based on cultural nuances. It's not just about literal translations; it's about conveying ideas naturally in the target language, preserving the original intent and tone.
Why LLaMA 3.1 Matters
-
Contextual Understanding: LLaMA 3.1 excels at grasping the broader context, ensuring translations that make sense beyond just the words used.
-
Long-form Coherence: Whether it's a short message or a lengthy document, this model maintains consistency and coherence throughout.
-
Cultural Adaptability: From formal business language to casual slang, LLaMA 3.1 adjusts its output to match the appropriate cultural and linguistic style.
In this tutorial, we'll dive deep into LLaMA 3.1's capabilities. We'll explore practical examples, examine code snippets, and uncover how to harness this technology for more accurate, culturally-aware translations.
Our goal is to equip you with the knowledge and tools to elevate your translation projects. Whether you're a developer, a linguist, or simply curious about the intersection of AI and language, this guide will provide valuable insights into the future of multilingual communication.
Let's embark on this journey to unlock the full potential of LLaMA 3.1 and revolutionize the way we bridge language barriers.
Setting Up Your LLaMA 3.1 Translation Project
To get started with our LLaMA 3.1 translation project, we'll need to set up our development environment and project structure. This guide will walk you through the process step-by-step.
Creating a Virtual Environment
First, let's create a virtual environment to isolate our project dependencies:
On Windows:
python -m venv venv
venv\Scripts\activate
On macOS/Linux:
python3 -m venv venv
source venv/bin/activate
Project Structure
Our project follows a specific structure for better organization. Create the following directory structure in your project root:
meta-llama3.1-boilerplate/
│
├── config/
│ ├── __init__.py
│ └── config.py
│
├── src/
│ ├── api/
│ │ ├── __init__.py
│ │ └── model_integration.py
│ │
│ ├── utils/
│ │ ├── __init__.py
│ │ └── prompt_templates.py
│ │
│ └── __init__.py
│
├── .env
├── app.py
├── main.py
├── README.md
└── requirements.txt
This structure separates configuration, source code, and utility functions, making the project more manageable as it grows.
API Key Setup
- Navigate to https://aimlapi.com/app/keys/
- Register for an account if you haven't already
- Click on "Create API Key" and copy the generated key
- Create a
.envfile in your project root and add your API key:
HOSTED_BASE_URL = https://api.aimlapi.com/v1
HOSTED_API_KEY = your_api_key_here
LOCAL_BASE_URL = http://localhost:11434/api/chat
Local Model Setup
Our project supports both hosted APIs and local model running. For local support:
-
Download OLLAMA from https://ollama.com/download
-
Install and run the application
-
Open a terminal and run:
ollama run llama3.1
This will download and run the LLaMA 3.1 8B model locally, making it available on localhost. Running the 8B model locally is quite feasible on modern laptops, offering a good balance of performance and accessibility for development purposes.
Got it! Here's how we can rewrite the section properly:
Installing Dependencies
To get the project up and running, you'll need to install a few key dependencies that are required for building the user interface, managing API requests, and handling environment variables. You can install all of them at once using the following command:
pip install streamlit openai requests Pillow python-dotenv
Add to requirements.txt
It's also a good practice to include these dependencies in a requirements.txt file, so anyone who works with the project can install them easily. Open or create a requirements.txt file in your project root and add the following lines:
streamlit
openai
requests
Pillow
python-dotenv
Once you've added these to your requirements.txt file, anyone can install the required dependencies by running:
pip install -r requirements.txt
This ensures that all the necessary libraries are installed in a consistent way for every user who works with the project.
Boilerplate Code: Jumpstart Your Development
To help you get started quickly and focus on what matters most—building your multilingual translation project—we've created a comprehensive boilerplate. This boilerplate provides a ready-to-use foundation, saving you from the time-consuming process of setting up the project structure and environment from scratch.
By using the boilerplate, you’ll benefit from:
- Pre-configured environment: The virtual environment setup and necessary dependencies are already prepared.
- Clean project structure: The boilerplate organizes your codebase in a way that’s scalable and maintainable, with clearly defined folders for configuration, source code, and utilities.
- Example usage: We've included working examples of how to integrate the LLaMA 3.1 model for translation, sentiment analysis, and cultural adaptation tasks, giving you a strong starting point.
You can clone or download the boilerplate from GitHub by following this link. This boilerplate is designed with best practices in mind, allowing you to focus on development without worrying about initial setup.
Why this matters:
- Save Time: All the groundwork is already done for you, allowing you to jump straight into development.
- Reduce Setup Hassles: The project is ready to go with configurations and structure in place. No need to reinvent the wheel.
- Scalability: The organized structure ensures that as your project grows, it remains easy to manage and scale.
Leverage this boilerplate to kickstart your LLaMA 3.1 project, and dive directly into building powerful, multilingual translation features without any friction.
High-Level Overview of the Project
This project is designed to demonstrate the multilingual translation capabilities of LLaMA 3.1, allowing users to seamlessly switch between hosted and locally deployed models for translating, analyzing sentiment, and explaining cultural references. Here's how the project is structured:
-
Configuration (
config/config.py): This file manages all the configuration settings, including API keys and base URLs for both hosted and local model setups. TheConfigclass helps keep the project flexible, making it easy to switch between different LLaMA models. -
API Model Integration (
src/api/model_integration.py): This file handles the communication with both the hosted LLaMA 3.1 API and the locally deployed model. It ensures that requests are sent to the correct endpoint and handles streaming responses for long texts, providing a seamless user experience. -
Prompt Templates (
src/utils/prompt_templates.py): This file defines the templates for various prompts, such as translations, sentiment analysis, and cultural references. These templates guide the LLaMA 3.1 model to generate accurate and context-aware responses, tailored to specific linguistic and cultural needs. -
Application Logic (
src/app.py): This is the main Streamlit application that users interact with. It allows users to input text for translation, select languages and cultural contexts, and view results in real-time. The app also supports additional analysis, such as sentiment and cultural reference breakdowns. -
Main Entry Point (
main.py): This file serves as the entry point for the entire application, triggering the app to run when executed. -
Environment File (
.env): The.envfile stores sensitive information like API keys and URLs. It keeps these variables separate from the codebase to enhance security.
Understanding the Configuration File (config/config.py)
The configuration file is the backbone of our project’s settings, responsible for handling all the essential environment variables and model configurations. It ensures that sensitive data like API keys and URLs are securely stored in environment variables, rather than being hardcoded into the source code. This approach keeps the project flexible, secure, and easy to adapt to different environments, whether you're using hosted models or running them locally.
In this file, the first step is to load environment variables using the dotenv package. This allows the program to access external settings, such as API keys, that are stored in a separate .env file. This separation of configuration from code is a best practice that enhances both security and scalability.
Here’s the complete code for the configuration file:
import os
from dotenv import load_dotenv
# Load environment variables from the .env file
load_dotenv()
class Config:
"""
A configuration class that retrieves environment variables and stores configuration settings.
"""
# API and Model configurations
HOSTED_BASE_URL = os.getenv("HOSTED_BASE_URL")
HOSTED_API_KEY = os.getenv("HOSTED_API_KEY")
LOCAL_BASE_URL = os.getenv("LOCAL_BASE_URL")
# Available models
AVAILABLE_MODELS = [
"meta-llama/Meta-Llama-3.1-405B-Instruct-Turbo",
"meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo",
"meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
"llama3.1",
]
Breaking Down the Code
The first thing this file does is load environment variables from the .env file using the load_dotenv() function. This step allows the application to access critical settings, such as the base URL for hosted models and API keys, without embedding these values directly into the code. By doing this, you can easily switch between different setups (e.g., using a local version of the model for testing versus a hosted version in production) simply by updating the .env file.
Next, we define the Config class, which stores key configuration details as class attributes. This class contains three important elements:
- API and Model Configurations:
HOSTED_BASE_URL,HOSTED_API_KEY, andLOCAL_BASE_URLretrieve their values from environment variables. These variables determine whether the project will use a hosted or local version of the LLaMA 3.1 model, giving us flexibility in how the application operates.
- Available Models:
AVAILABLE_MODELSis a list of all the available LLaMA 3.1 models that the project can interact with. These models include various sizes and versions, from 8B to 405B, allowing the user to choose the right model based on their specific translation needs. Whether you're running the model locally or using a hosted version, the project is set up to handle both scenarios efficiently.
This separation of concerns—where the configuration logic is centralized in one file—makes it easy to manage and scale the project. As you add more features, change models, or switch environments, the Config class will keep everything running smoothly without the need for major code modifications.
Now that we’ve covered the configuration, we’ll move on to the API model integration, where we handle communication between the project and the LLaMA 3.1 model, whether hosted or running locally.
API Model Integration (src/api/model_integration.py)
In this section, we handle the crucial part of the project—communicating with the LLaMA 3.1 model to perform translations, sentiment analysis, or other tasks. Whether the model is hosted remotely via an API or running locally, this file ensures that the right requests are made and responses are properly processed.
The API integration is split into two main approaches: one for hosted models (via OpenAI’s API) and another for models running locally on your machine. This dual approach allows you to easily switch between environments while keeping the same project structure.
Here’s the complete code for the model integration file:
import requests
import json
from openai import OpenAI
from config.config import Config
def get_api_config(model_name):
"""
Get API base URL and API key based on the model name.
"""
if model_name.startswith("meta-llama/"):
return Config.HOSTED_BASE_URL, Config.HOSTED_API_KEY
elif model_name == "llama3.1":
return Config.LOCAL_BASE_URL, None
else:
raise ValueError(f"Invalid model name: {model_name}")
def handle_hosted_request(client, model_name, messages, container):
"""
Handles the hosted Llama 3.1 model requests via OpenAI's API.
"""
try:
stream = client.chat.completions.create(
model=model_name,
messages=messages,
stream=True,
)
response_placeholder = container.empty()
full_response = ""
for chunk in stream:
if chunk.choices[0].delta.content is not None:
full_response += chunk.choices[0].delta.content
response_placeholder.markdown(full_response + "▌")
response_placeholder.markdown(full_response)
return full_response
except Exception as e:
error_message = f"API Error: {str(e)}"
container.error(error_message)
return None
def handle_local_request(base_url, model_name, messages, container):
"""
Handles requests to the locally hosted Llama 3.1 model.
"""
try:
payload = {
"model": model_name,
"messages": messages,
"stream": True,
}
headers = {"Content-Type": "application/json"}
response_placeholder = container.empty()
full_response = ""
with requests.post(
base_url, json=payload, headers=headers, stream=True
) as response:
response.raise_for_status()
for line in response.iter_lines():
if line:
try:
chunk = json.loads(line)
if "done" in chunk and chunk["done"]:
break
if "message" in chunk and "content" in chunk["message"]:
content = chunk["message"]["content"]
full_response += content
response_placeholder.markdown(full_response + "▌")
except json.JSONDecodeError:
pass
response_placeholder.markdown(full_response)
return full_response
except requests.RequestException as e:
error_message = f"API Error: {str(e)}"
container.error(error_message)
return None
def stream_response(messages, container, model_name):
"""
This function handles the API request based on the model (hosted or local) and streams the response.
"""
base_url, api_key = get_api_config(model_name)
if model_name.startswith("meta-llama/"):
client = OpenAI(api_key=api_key, base_url=base_url)
return handle_hosted_request(client, model_name, messages, container)
elif model_name == "llama3.1":
return handle_local_request(base_url, model_name, messages, container)
else:
raise ValueError("Unsupported model selected.")
Breaking Down the Code
The first step in interacting with the model is determining whether the model is hosted remotely or running locally. This is done using the get_api_config() function. Depending on the model name passed, the function returns the appropriate API base URL and API key for hosted models or the local URL if you're using a locally running instance of LLaMA 3.1.
Once the base URL is determined, the program sends requests to either the hosted model or the local model, with both scenarios being handled by separate functions: handle_hosted_request() and handle_local_request().
Handling Hosted Requests
For hosted models, we use OpenAI's API to send chat completion requests. The model streams responses back as it processes the text. This method is particularly useful for handling longer text inputs because the response can be displayed incrementally. The handle_hosted_request() function is designed to catch errors and ensure the user is informed if something goes wrong during the request.
Handling Local Requests
When using a local model, the handle_local_request() function takes over. It constructs a POST request to the locally hosted instance of LLaMA 3.1 and processes the response in chunks, similar to how we handle hosted responses. The key difference is that this function interacts directly with the locally running server using requests.post(). Just like with the hosted requests, this function includes error handling to manage issues like network failures or invalid data.
Stream Response
Finally, the stream_response() function determines which type of request (hosted or local) needs to be sent. It acts as the decision-making layer of the API integration, directing the request to the appropriate handler function based on the model name. This abstraction keeps the main code clean, as developers don’t have to worry about the details of which environment the model is running in.
This entire structure provides a flexible, scalable way to manage requests to LLaMA 3.1, whether you're using a powerful cloud-based model or running it locally on your own hardware. Now that we’ve explored how the model is integrated, we’ll next look at how to interact with the model using various prompt templates.
Prompt Templates (src/utils/prompt_templates.py)
This file contains functions that generate well-structured prompts for interacting with LLaMA 3.1. These prompts guide the model to perform various tasks such as translation, sentiment analysis, and cultural reference explanation. The way a prompt is crafted can significantly influence the quality of the model's output. Here, we are focusing on four key functions that cover translation, sentiment analysis, cultural reference explanation, and interactive translations.
get_translation_prompt()
This function constructs a detailed prompt that asks the LLaMA 3.1 model to perform a translation while adapting the output to fit a specific cultural context. The prompt not only focuses on literal translation but also encourages the model to think about how cultural nuances should influence the final result.
def get_translation_prompt(text, source_lang, target_lang, cultural_context):
"""
Returns a prompt for translating the given text while considering cultural context.
"""
return f"""
As an advanced cultural translation assistant, translate the following text from {source_lang} to {target_lang}, adapting it to a {cultural_context} context:
"{text}"
Provide your response in markdown format as follows, using Streamlit's markdown capabilities for enhanced visual appeal:
## :blue[Translation]
> [Your translated text here]
## :green[Cultural Adaptations]
- **Adaptation 1**: [Explanation]
- **Adaptation 2**: [Explanation]
[Add more adaptations as needed]
## :orange[Alternative Phrasings]
1. ":violet[Original phrase]" → ":rainbow[Alternative 1]", ":rainbow[Alternative 2]"
- _Context_: [Explain when to use each alternative]
## :red[Linguistic Analysis]
- **Register**: [Formal/Informal/etc.]
- **Tone**: [Describe the tone of the translation]
- **Key Challenges**: [Discuss any particularly challenging aspects of the translation]
"""
Explanation:
- The function accepts four parameters:
text,source_lang,target_lang, andcultural_context. - It returns a string that forms the entire prompt. The prompt structure includes different sections, such as the main translation, cultural adaptations, alternative phrasings, and a linguistic analysis.
- This approach ensures that the translation is not only accurate but also culturally sensitive and adaptable to various contexts, like formal or casual settings.
get_sentiment_analysis_prompt()
This function is designed to prompt the LLaMA 3.1 model to perform a sentiment analysis on a given text. It encourages the model to break down the sentiment into categories such as positivity, negativity, and neutrality, and also to explore emotional indicators present in the text.
def get_sentiment_analysis_prompt(text, source_lang):
"""
Returns a prompt for conducting sentiment analysis on a given text.
"""
return f"""
Conduct a comprehensive sentiment analysis of the following {source_lang} text:
"{text}"
Provide your analysis in markdown format as follows:
## :blue[Overall Sentiment]
[Positive/Negative/Neutral/Mixed]
## :green[Sentiment Breakdown]
- **Positivity**: :smile: [Score from 0 to 1]
- **Negativity**: :frowning: [Score from 0 to 1]
- **Neutrality**: :neutral_face: [Score from 0 to 1]
## :orange[Key Emotional Indicators]
1. **:heart: [Emotion 1]**:
- _Evidence_: ":violet[Relevant quote from text]"
- _Explanation_: [Brief analysis]
## :earth_americas: Cultural Context
[Explain how the sentiment might be perceived in the {source_lang}-speaking culture, considering any cultural-specific expressions or connotations]
"""
Explanation:
- This function takes two parameters:
textandsource_lang. - The prompt it generates asks the model to analyze the overall sentiment of the text, breaking it down into specific categories (e.g., positivity, negativity, neutrality) and assigning scores to each.
- The function also prompts the model to explore key emotional indicators and their relevance within the cultural context of the source language. This provides a deep analysis of how different audiences might perceive the sentiment behind the text.
get_cultural_reference_explanation_prompt()
This function generates a prompt that asks the LLaMA 3.1 model to explain cultural references found in a text. It’s designed for cases where a concept in one language may not easily translate into another due to differences in cultural background.
def get_cultural_reference_explanation_prompt(text, source_lang, target_lang):
"""
Returns a prompt to explain cultural references in a source language for a target language audience.
"""
return f"""
As a cross-cultural communication expert, explain the cultural references in this {source_lang} text for someone from a {target_lang} background:
"{text}"
## :earth_americas: Cultural References
1. **:star: [Reference 1]**
- _Meaning_: :blue[Explanation]
- _Cultural Significance_: :green[Brief description]
- _{target_lang} Equivalent_: :orange[Equivalent or similar concept, if applicable]
- _Usage Example_: ":violet[Show how it's used in a sentence]"
2. **:star: [Reference 2]**
- _Meaning_: :blue[Explanation]
- _Cultural Significance_: :green[Brief description]
- _{target_lang} Equivalent_: :orange[Equivalent or similar concept, if applicable]
- _Usage Example_: ":violet[Show how it's used in a sentence]"
## :globe_with_meridians: Overall Cultural Context
[Summarize the cultural differences relevant to this text.]
"""
Explanation:
- The function accepts three parameters:
text,source_lang, andtarget_lang. - The prompt it generates helps the model break down cultural references in a way that makes sense to someone from a different cultural background.
- The model is asked to explain the significance of these references, their meaning, and provide equivalent concepts in the target language, if applicable. This makes it useful for translating texts that contain idioms, metaphors, or culturally specific references that don't have direct translations.
get_interactive_translation_prompt()
This function creates a prompt for performing a more interactive and detailed translation. The prompt not only focuses on the translation itself but also includes sections for contextual usage, word etymology, and usage notes, making it ideal for cases where deeper linguistic insights are needed.
def get_interactive_translation_prompt(text, source_lang, target_lang):
"""
Returns a prompt for providing an interactive, detailed translation with context.
"""
return f"""
Translate the following text from {source_lang} to {target_lang} and provide an overall analysis of its meaning, usage, and cultural relevance:
"{text}"
## :books: General Translation
**Text** → ":blue[Overall translation]"
## :arrows_counterclockwise: Contextual Usage and Adaptation
1. ":green[Context 1]" - _Explanation_: [How the translation adapts to cultural context]
2. ":orange[Context 2]" - _Explanation_: [Alternative contextual usage]
## :dna: Etymology and Origin
- **Origin**: :violet[Brief description of word origins or key concepts]
- **Related concepts**: :rainbow[If applicable, related words or phrases]
## :memo: Usage Notes
- **Register**: :blue[Formal/Informal/etc.]
- **Connotations**: :green[Positive/Negative connotations of the translation]
- **Cultural Significance**: :orange[Explain the cultural impact or relevance of the translation]
"""
Explanation:
- This function takes three parameters:
text,source_lang, andtarget_lang. - The generated prompt provides a detailed translation, but it also asks the model to explore contextual usage, explain word etymology, and provide notes on the register (formal or informal) and connotations (positive or negative).
- This is particularly useful for complex translations where the reader needs to understand not only the literal meaning but also the broader context in which certain words or phrases are used.
Why This Matters
These prompt templates are essential for guiding the LLaMA 3.1 model to produce nuanced, context-aware responses. The templates ensure that translations, sentiment analyses, and cultural explanations are accurate, culturally sensitive, and informative. By providing a structured framework for interacting with the model, these prompts significantly enhance the quality and relevance of the outputs.
Next, we'll move on to the application logic, where these prompts are used to generate real-time translations and analyses through the Streamlit app.
Application Logic (src/app.py)
The application logic in app.py serves as the core of the user interface, built using Streamlit, a Python-based framework that simplifies the process of creating interactive web apps. This file brings everything together, allowing users to interact with the LLaMA 3.1 model via a web-based interface where they can input text for translation, sentiment analysis, or cultural reference exploration.
Here’s the code for the application logic:
import streamlit as st
from src.api.model_integration import stream_response
from src.utils.prompt_templates import (
get_translation_prompt,
get_sentiment_analysis_prompt,
get_cultural_reference_explanation_prompt,
get_interactive_translation_prompt,
)
from config.config import Config
def setup_page():
"""
Sets up the page with custom styles and page configuration.
"""
st.set_page_config(
page_title="Advanced Llama 3.1 Cultural Translator",
layout="wide",
initial_sidebar_state="expanded",
)
st.markdown(
"""
<style>
:root {
--llama-color: #4e8cff;
--llama-color-light: #e6f0ff;
--llama-color-dark: #1a3a6c;
--llama-gradient-start: #4e54c8;
--llama-gradient-end: #8f94fb;
}
.stApp {
margin: auto;
background-color: var(--background-color);
color: var(--text-color);
}
.logo-container {
display: flex;
justify-content: center;
margin-bottom: 1rem;
}
.logo-container img {
width: 150px;
}
</style>
""",
unsafe_allow_html=True,
)
def main():
setup_page()
# Header section with title and subtitle
st.markdown(
"""
<div style="text-align: center;">
<h1 class="header-title">🦙 Meta-Llama 3.1 Cultural Translator</h1>
<p class="header-subtitle">Powered by Meta's advanced language models</p>
</div>
""",
unsafe_allow_html=True,
)
# Meta logo
st.markdown(
"""
<div class="logo-container">
<img src="https://upload.wikimedia.org/wikipedia/commons/7/7b/Meta_Platforms_Inc._logo.svg" alt="Meta Logo">
</div>
""",
unsafe_allow_html=True,
)
# Remove the Llama image display
# Sidebar for settings
with st.sidebar:
st.title("🦙 Llama Translator Settings")
model_name = st.selectbox("Choose a model", Config.AVAILABLE_MODELS)
source_lang = st.selectbox(
"From", ["English", "Spanish", "French", "German", "Japanese"]
)
target_lang = st.selectbox(
"To", ["Spanish", "English", "French", "German", "Japanese"]
)
cultural_context = st.selectbox(
"Context", ["Formal", "Casual", "Business", "Youth Slang", "Poetic"]
)
# Main container with border
main_container = st.container(border=True)
with main_container:
st.header("Enter Text for Translation and Analysis")
text = st.text_area(
"Text to translate",
"It was the best of times, it was the worst of times...",
height=200,
)
st.caption(f"Character count: {len(text)}")
if st.button("Translate and Analyze", type="primary"):
if text:
# Tabs for different analysis types
tab1, tab2, tab3, tab4 = st.tabs(
[
"Translation",
"Sentiment Analysis",
"Cultural References",
"Interactive Translation",
]
)
# Tab 1: Translation
with tab1:
st.subheader("Translation Result")
translation_container = st.empty()
translation_prompt = get_translation_prompt(
text, source_lang, target_lang, cultural_context
)
translation = stream_response(
[{"role": "user", "content": translation_prompt}],
translation_container,
model_name,
)
# Tab 2: Sentiment Analysis
with tab2:
st.subheader("Sentiment Analysis")
sentiment_container = st.empty()
sentiment_prompt = get_sentiment_analysis_prompt(text, source_lang)
sentiment_analysis = stream_response(
[{"role": "user", "content": sentiment_prompt}],
sentiment_container,
model_name,
)
# Tab 3: Cultural References
with tab3:
st.subheader("Cultural References")
cultural_container = st.empty()
cultural_prompt = get_cultural_reference_explanation_prompt(
text, source_lang, target_lang
)
cultural_references = stream_response(
[{"role": "user", "content": cultural_prompt}],
cultural_container,
model_name,
)
# Tab 4: Interactive Translation
with tab4:
st.subheader("Interactive Translation")
interactive_container = st.empty()
interactive_prompt = get_interactive_translation_prompt(
text, source_lang, target_lang
)
interactive_translation = stream_response(
[{"role": "user", "content": interactive_prompt}],
interactive_container,
model_name,
)
# Sidebar for additional information and feedback
with st.sidebar:
st.subheader("About")
st.info("This app demonstrates Meta's Llama 3.1 capabilities.")
st.subheader("Feedback")
feedback = st.text_area("Leave your feedback here", height=100)
if st.button("Submit Feedback"):
st.success("Thank you for your feedback!")
if __name__ == "__main__":
main()
Explanation of Application Logic
This file is the interactive front-end for the LLaMA 3.1 translator project. It’s responsible for rendering the user interface, allowing users to input text, select translation models, and perform analyses using the LLaMA 3.1 model. Built with Streamlit, it provides an intuitive and easy-to-use web interface that dynamically updates based on user input.
setup_page()
This function sets up the basic layout and configuration for the Streamlit app. It defines the page title, layout style (e.g., wide layout), and initial sidebar state. It also applies custom CSS styles for a polished appearance, ensuring a professional look for the app.
- The function customizes page visuals, including background colors, font colors, and logo placement, to create a cohesive and visually appealing interface.
main()
The main() function is where the primary logic of the application takes place. It orchestrates the layout, user input, and interaction with the LLaMA 3.1 model.
-
Header and Logo: The header section sets the tone of the application with a title and subtitle, and includes the Meta logo to reinforce the branding.
-
Sidebar for Settings: Users can select the model they want to use, as well as the source and target languages. They can also choose the cultural context in which the translation should be made (e.g., formal, casual, business, etc.). This flexibility allows for more personalized translations.
-
Main Text Area: The text area is where users input the text they want to translate. A character counter is displayed to keep track of the input size.
-
Tabs for Results: After inputting the text, users can view the translation and various analyses (e.g., sentiment analysis, cultural references) in different tabs. Each tab corresponds to a different functionality offered by the LLaMA 3.1 model, and the results are displayed dynamically as the user interacts with the app.
Streaming Responses
For each analysis or translation, the stream_response() function is used to handle real-time interaction with the LLaMA 3.1 model. Depending on the selected model (hosted or local), this function communicates with the API and streams the response to the UI in real time. This ensures that users see incremental updates when dealing with long-form text or complex translations.
User Feedback Section
Finally, the app includes a feedback section where users can provide feedback on their experience using the translator. This is a useful feature for gathering insights and continuously improving the app based on user input.
This file brings together the power of LLaMA 3.1 with a clean, user-friendly interface, allowing for smooth interaction with the model and real-time translation and analysis capabilities. Next, we’ll look at how the app is executed through the main.py file.
Main Entry Point (main.py)
The main.py file serves as the entry point for our project, responsible for launching the application when the script is executed. It is a simple yet crucial part of the project structure because it ensures that the application logic is run correctly.
Here’s the code for main.py:
from src.app import main
if __name__ == "__main__":
main()
Explanation
This file is minimal but serves an essential function. It imports the main() function from src/app.py, which contains the core application logic. The if __name__ == "__main__": statement ensures that this script will only execute the main() function if it is run directly, rather than being imported as a module in another file.
This design pattern is useful for separating concerns—keeping the logic of the app in app.py while using main.py solely to handle the app’s execution.
Why It's Important
The simplicity of main.py reflects a best practice in Python programming: separating the main execution flow from the core logic of your project. This makes the project easier to maintain and extend, especially as you add new features or functionalities.
For example, if you wanted to modify the application (such as running unit tests or adding a new feature), main.py stays clean and focused solely on initiating the app. Meanwhile, all the core logic and components remain modular and well-structured in their respective files.
With main.py in place, the entire application can be launched with a simple command:
streamlit run main.py
This single line triggers the Streamlit application, loads the configuration, and starts the user interface where the LLaMA 3.1 model can be interacted with.
Demo: How the LLaMA 3.1 Translator Works
Below are some screenshots that illustrate the core features and functionality of the LLaMA 3.1 translator. These images showcase how easy it is to interact with the model through a user-friendly interface.
1. Input Text for Translation
In this section, you can input the text that needs to be translated. You can select the source and target languages, as well as the cultural context (e.g., Formal, Casual, Business). Once you enter your text and select the appropriate settings, you can click "Translate and Analyze" to get started.
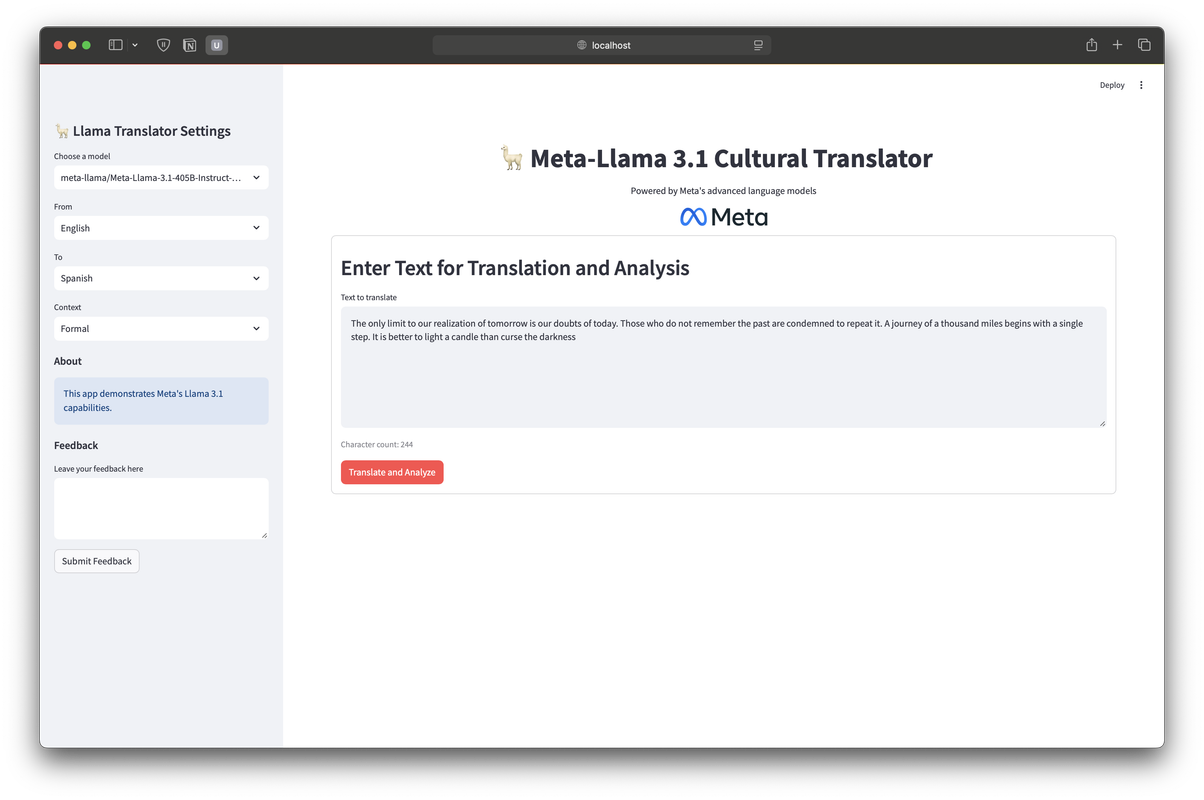
2. Language Selection: From Source Language
Here, you can choose the language from which the text will be translated. The available options include popular languages like English, Spanish, French, German, and Japanese.
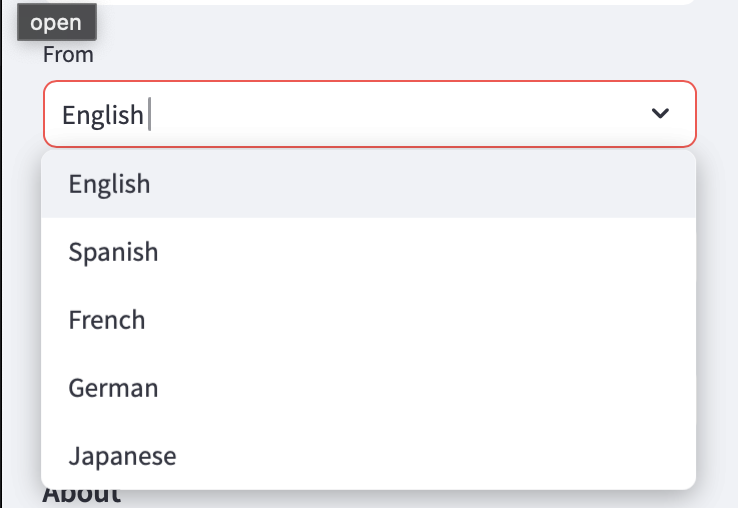
3. Language Selection: To Target Language
After selecting the source language, you can pick the target language to translate the text into. The interface provides a dropdown with a similar set of options.
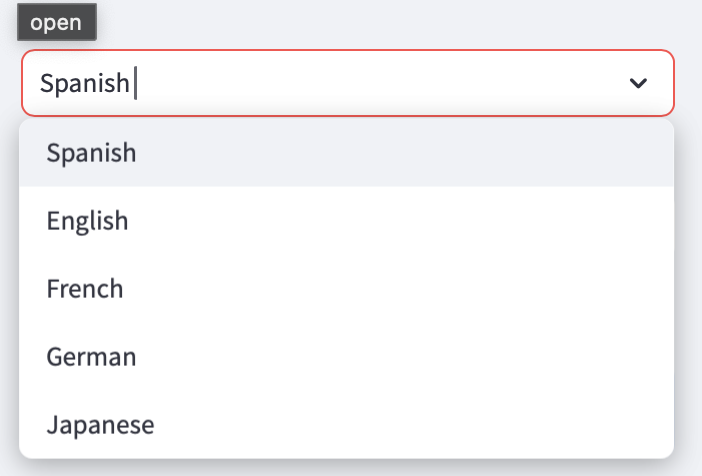
4. Cultural Context Options
One of the unique aspects of this translator is the ability to choose the cultural context. You can choose between formal, casual, business, youth slang, or poetic contexts, ensuring the translated text fits the right tone and style.
5. Translation and Cultural Adaptations
After submitting the text, you'll get a detailed translation result, including cultural adaptations to ensure the text fits appropriately within the target language's cultural context. Additionally, alternative phrasings are provided, along with a linguistic analysis that breaks down the translation's tone, register, and key challenges.
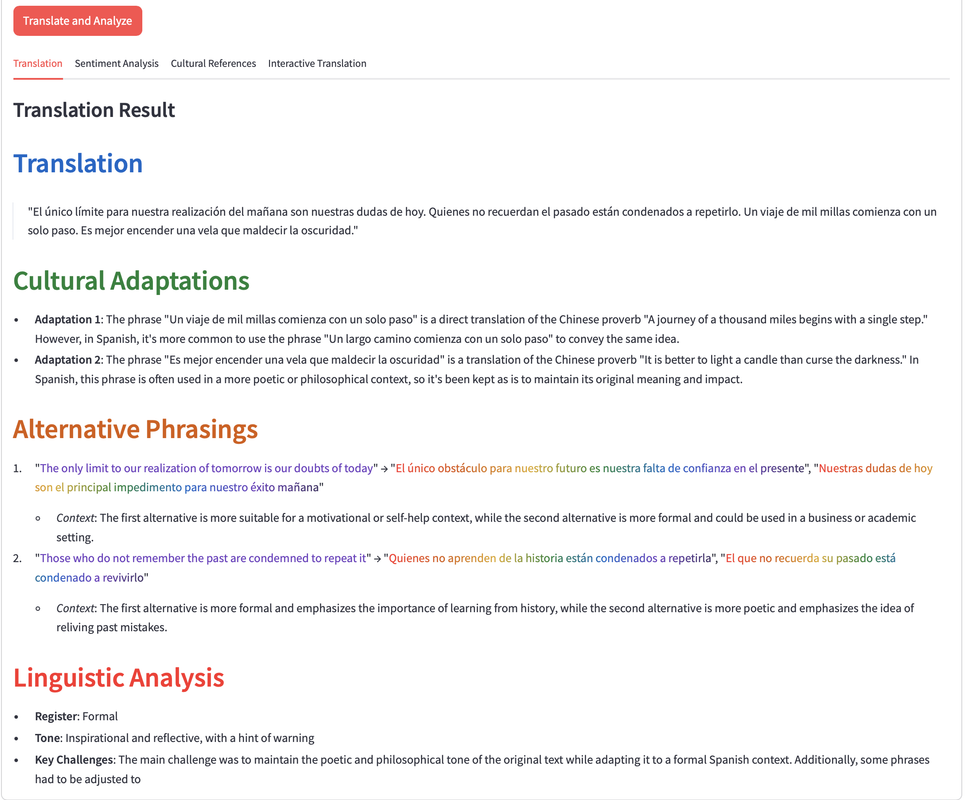
6. Sentiment Analysis
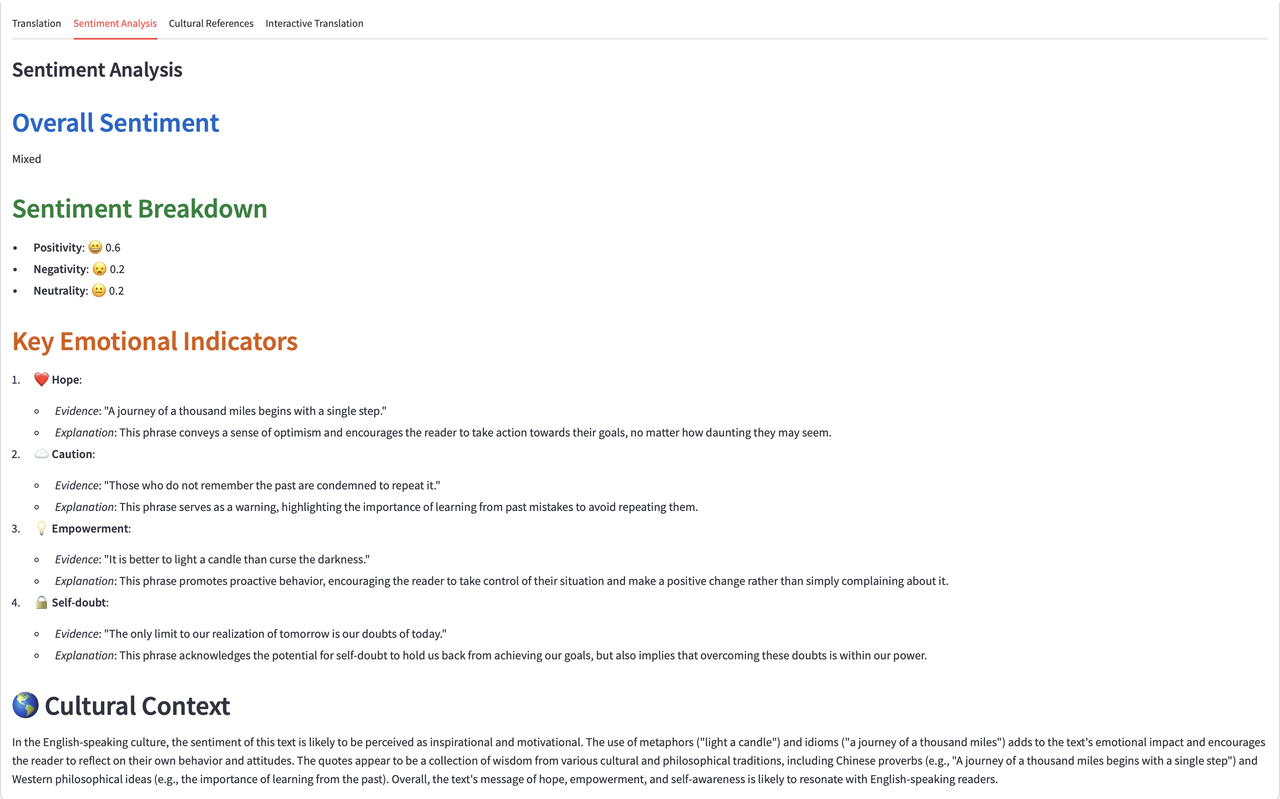
This feature analyzes the emotional tone of the input text, providing a breakdown of overall sentiment (positive, negative, or neutral). It also lists key emotional indicators such as hope, caution, empowerment, and more, making it easy to see the underlying feelings expressed in the text.
7. Cultural Reference Explanation
If the text includes cultural references that may not translate directly, this feature will explain those references in detail. For each reference, the tool provides a meaning, cultural significance, equivalent in the target language, and usage examples. This ensures the translation is contextually accurate and meaningful.

8. Interactive Translation
The interactive translation feature not only provides a straightforward translation but also explains the context and origin of the phrases. It includes sections for contextual usage, etymology, and register to help understand the deeper meaning of the translated text. This is especially useful for texts with historical or philosophical significance.
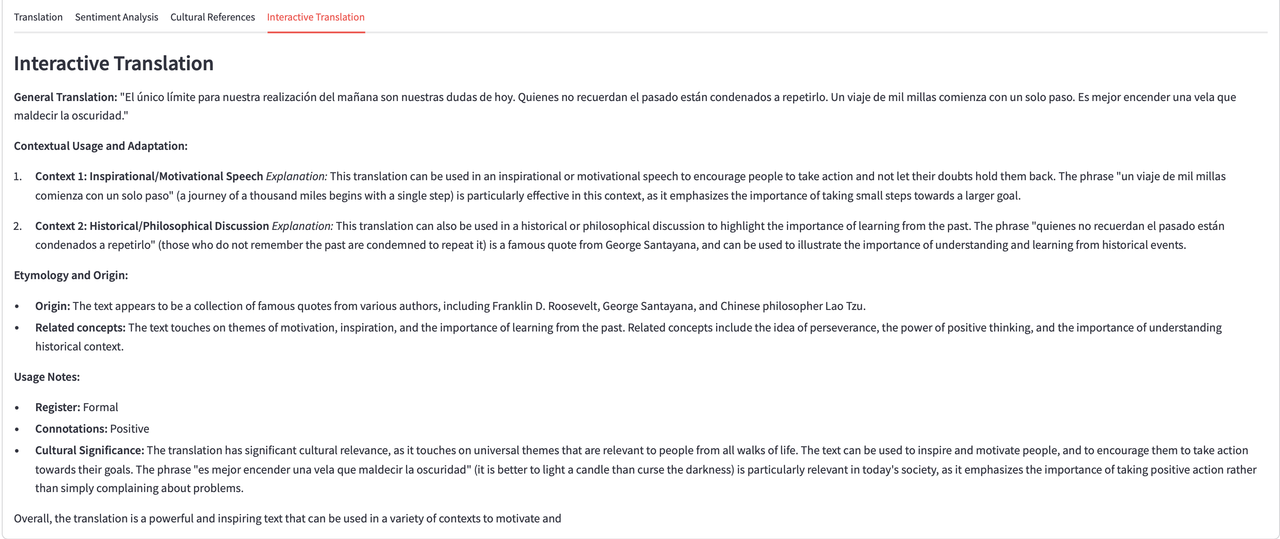
These final screenshots showcase the detailed results that the LLaMA 3.1 translator can provide, emphasizing not just literal translations but also deeper insights into cultural context and sentiment.
Conclusion
This tutorial has guided you through the setup and execution of a LLaMA 3.1-powered multilingual translation project. From the configuration file that manages environment settings to the Streamlit app that brings everything together, each part of the project plays a vital role in delivering accurate and culturally aware translations.
To summarize:
- Configuration (
config/config.py) handles sensitive settings and model options, allowing flexibility between hosted and local setups. - Model Integration (
src/api/model_integration.py) manages communication with both hosted and local models, ensuring that translation requests are processed and returned in real-time. - Prompt Templates (
src/utils/prompt_templates.py) define how tasks such as translation, sentiment analysis, and cultural reference explanation are structured and executed by LLaMA 3.1. - Application Logic (
src/app.py) creates an intuitive user interface where users can interact with the LLaMA 3.1 model, input text, and receive detailed results. - Main Entry (
main.py) acts as the launch point for the application, keeping the app execution clean and separate from the core logic. .envFile ensures security and flexibility by storing sensitive data and environment-specific configurations.
With this setup, you now have a robust framework for leveraging the power of LLaMA 3.1 for multilingual translations, sentiment analysis, and more.
Feel free to extend this project by adding additional features or exploring more advanced models as they become available. Happy coding!


