Cohere tutorial: Semantic Search with Cohere
What is semantic search?
What is semantic search, you ask? Well, let's dive into this intriguing concept. Semantic search is the ability of computers to search by meaning, transcending the usual keyword matching search. It's like having a conversation with your search engine, where it understands not just what you're asking, but why you're asking it. This is where the magic of natural language processing, artificial intelligence, and machine learning come into play. They work together to comprehend the user's query, the context of the query, and the user's intent. Semantic search examines the relationship between words, or the meaning of words, to provide more accurate and relevant search results than traditional keyword searches.
Now, semantic search engines aren't just a cool concept, they have many practical applications. For instance, have you ever noticed StackOverflow's "similar questions" feature? That's powered by a semantic search engine. They can also be used to build a private search engine for internal documents or records.
But how do you build such a tool? This is where our Cohere tutorial comes into play. We'll show you how to build a basic semantic search engine using Cohere. This Cohere tutorial covers the usage of an archive of questions to embed, search with an index and nearest neighbour search, and visualization based on the embeddings. So, whether you're looking to build a Cohere app or just want to learn how to use Cohere, this guide has got you covered.
Let's get started
For this Cohere AI tutorial we will use the example data that is provided by Cohere. You can use notebook code
First we will get get the archive of questions, then embed them and finally search using an index and nearest neighbour search. At the end we will visualize the results based on the embeddings. To run this tutorial you will need to have a Cohere account.
Lets start by installing the necessary libraries.
!pip install cohere umap-learn altair annoy datasets tqdm
Then create a new notebook or Pythin file and import the necessary libraries.
import cohere
import numpy as np
import re
import pandas as pd
from tqdm import tqdm
from datasets import load_dataset
import umap
import altair as alt
from sklearn.metrics.pairwise import cosine_similarity
from annoy import AnnoyIndex
import warnings
warnings.filterwarnings('ignore')
pd.set_option('display.max_colwidth', None)
Get the Archive of Questions
Next, we will get the archive of questions from Cohere. This archive is the trec
dataset, which is a collection of questions with categories. We will use the load_dataset function from the datasets library
to load the dataset.
# Get dataset
dataset = load_dataset("trec", split="train")
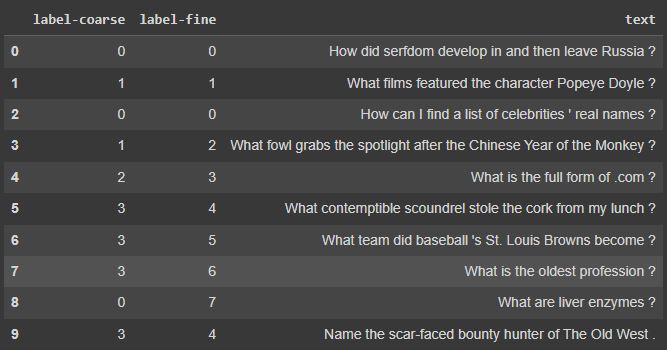
# Import into a pandas dataframe, take only the first 1000 rows
df = pd.DataFrame(dataset)[:1000]
# Preview the data to ensure it has loaded correctly
df.head(10)
Embed the Archive of Questions
Now we can embed the questions using Cohere. We will use the embed function from the Cohere library to embed the questions.
It should only take a few seconds to generate one thousand embeddings of this length.
# Paste your API key here. Remember to not share publicly
api_key = ''
# Create and retrieve a Cohere API key from dashboard.cohere.ai/welcome/register
co = cohere.Client(api_key)
# Get the embeddings
embeds = co.embed(texts=list(df['text']),
model='large',
truncate='LEFT').embeddings
Now we can build the index and search for the nearest neighbours. We will use the AnnoyIndex function from the annoy library.
The optimization problem of finding the point in a given set that is closest (or most similar) to a given point is known as nearest neighbour search.
# Create the search index, pass the size of embedding
search_index = AnnoyIndex(embeds.shape[1], 'angular')
# Add all the vectors to the search index
for i in range(len(embeds)):
search_index.add_item(i, embeds[i])
search_index.build(10) # 10 trees
search_index.save('test.ann')
Find the Neighbours of an example from the dataset
We can use the index we built to find the nearest neighbours of both existing questions and new questions that we embed. If we're only interested in measuring the similarities between the questions in the dataset (no outside queries) a simple way is to calculate the similarities between every pair of embeddings we have.
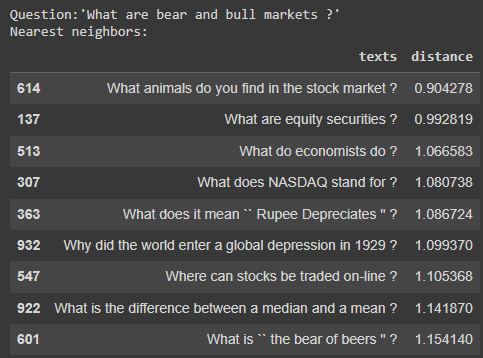
# Choose an example (we'll retrieve others similar to it)
example_id = 92
# Retrieve nearest neighbors
similar_item_ids = search_index.get_nns_by_item(example_id,10,
include_distances=True)
# Format and print the text and distances
results = pd.DataFrame(data={'texts': df.iloc[similar_item_ids[0]]['text'],
'distance': similar_item_ids[1]}).drop(example_id)
print(f"Question:'{df.iloc[example_id]['text']}'\nNearest neighbors:")
results # only in notebooks, use print(results) in scripts
Find the Neighbours of a User Query
We can use a technique such as embedding to find the nearest neighbours of a user query. By embedding the query, we can measure its similarity with items in the dataset and identify the closest neighbours.
Visualization
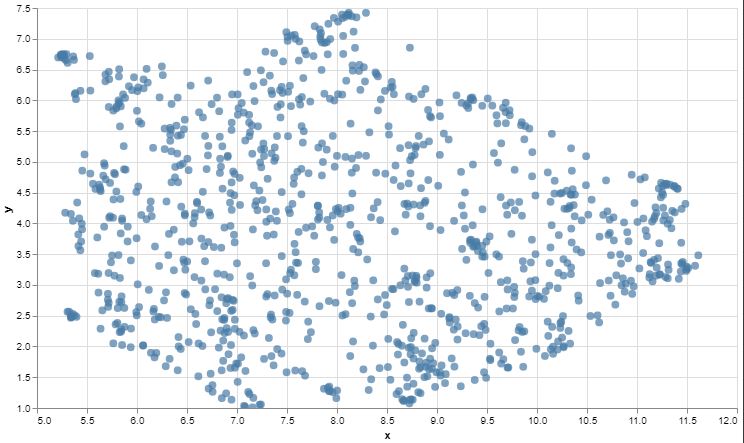
#@title Plot the archive {display-mode: "form"}
# UMAP reduces the dimensions from 1024 to 2 dimensions that we can plot
reducer = umap.UMAP(n_neighbors=20)
umap_embeds = reducer.fit_transform(embeds)
# Prepare the data to plot and interactive visualization
# using Altair
df_explore = pd.DataFrame(data={'text': df['text']})
df_explore['x'] = umap_embeds[:,0]
df_explore['y'] = umap_embeds[:,1]
# Plot
chart = alt.Chart(df_explore).mark_circle(size=60).encode(
x=#'x',
alt.X('x',
scale=alt.Scale(zero=False)
),
y=
alt.Y('y',
scale=alt.Scale(zero=False)
),
tooltip=['text']
).properties(
width=700,
height=400
)
chart.interactive()
Unleashing the Power of Semantic Search: A Cohere Tutorial
As we wrap up this introductory guide on semantic search using sentence embeddings, it's clear that the journey is just beginning. When constructing a search product, there are additional factors to consider. For instance, handling lengthy texts or training to optimize the embeddings for a particular purpose are crucial steps in the process.
This Cohere tutorial has set the foundation, but the world of semantic search is vast and ripe for exploration. Feel free to dive in, experiment with other data, and push the boundaries of what's possible. Whether you're aiming to build a Cohere app, seeking a comprehensive Cohere tutorial, or curious about how to use Cohere, the path forward is filled with exciting opportunities.
If you want to test what you have learned you can join our AI hackathons.
Identify a problem around you and build cohere app to fix it.
Thank you! If you enjoyed this tutorial you can find more and continue reading on our tutorial page - Fabian Stehle, Data Science Intern at New Native

Dev from Germany 🚀

.png&w=3840&q=75)