How Magic.dev’s LTM-2-mini is Redefining AI’s Ability to Handle Vast Contexts
How Magic.dev’s LTM-2-mini is Redefining AI’s Ability to Handle Vast Contexts
Lare Language Models have seen many gradual improvements—better algorithms, faster processors, and more data storage. But sometimes, a single innovation changes everything. Magic.dev's LTM-2-mini is one such breakthrough, capable of handling a 100 million token context window. This isn't just a technical upgrade; it's a significant leap that could redefine what AI can accomplish.
Having worked in the AI industry for years, I've witnessed how limitations in processing large amounts of data have held us back. Traditional models struggle with efficiency when dealing with vast datasets, making them less effective in complex, real-world applications. The introduction of LTM-2-mini marks a turning point—it enables AI systems to handle immense datasets with remarkable efficiency and accuracy.
Why the 100 Million Token Context Window Is a Game-Changer
To appreciate the significance of a 100 million token context window, it's essential to understand what a token represents in AI models. Tokens are the basic units of data—words, phrases, or symbols—that models use to interpret and generate language. Most current models operate within context windows of a few thousand tokens at best. This limitation means they can only consider a relatively small amount of information when making predictions or generating responses.
Imagine trying to understand a complex legal document or an extensive codebase while only being able to see a few paragraphs at a time. Critical context and connections would be missed, leading to misunderstandings or errors. LTM-2-mini obliterates this barrier by allowing the model to process the equivalent of 10 million lines of code or 750 novels simultaneously. This expansive context window enables the AI to comprehend and analyze data on a scale that closely mirrors human cognitive capabilities.
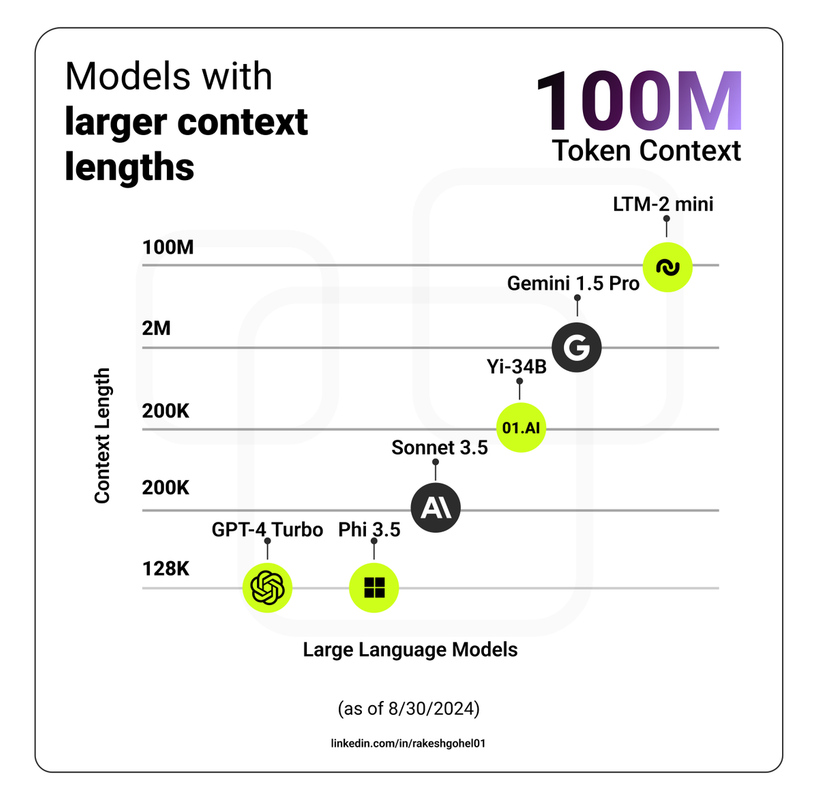
Comparing LTM-2-mini to Other AI Models
To understand the significance of LTM-2-mini, it's helpful to compare it with other models that have attempted to expand context windows and improve efficiency.
Traditional AI Models and Their Limitations
Most existing AI language models, like earlier versions of GPT or models such as Llama 2, operate with context windows ranging from a few thousand tokens up to around 32,000 tokens in advanced cases. This means they can only consider a limited amount of information when generating responses or making predictions. Tasks requiring comprehension of lengthy documents, extensive codebases, or large datasets often exceed these limitations.
As context windows increase, traditional models face exponential growth in computational demands due to the nature of attention mechanisms. This makes processing large contexts not only slow but also resource-intensive, often requiring substantial hardware investments that aren't practical for most applications.
Llama 3.1's Approach
Llama 3.1 made strides by attempting to expand context windows. However, even with significant advancements, it handles far fewer tokens than LTM-2-mini. Running Llama 3.1 with a 100 million token context window is practically infeasible—it would require over 600 high-end GPUs just to store the necessary key-value (KV) cache. This immense resource requirement renders such an approach impractical outside of highly specialized environments.
Anthropic's Claude and Extended Contexts
Anthropic's Claude has explored extended context windows, supporting up to 100,000 tokens in some versions. While this is a notable improvement over earlier models, it still falls short compared to LTM-2-mini's capabilities. Even at this level, models like Claude encounter challenges with computational efficiency and maintaining performance over extended contexts.
OpenAI's GPT-4 and Context Limitations
OpenAI's GPT-4, one of the most advanced language models available, typically operates with a context window of up to 8,192 tokens, with some versions extending to 32,768 tokens. While GPT-4 delivers impressive performance within these limits, it cannot process the massive context sizes that LTM-2-mini handles. This restricts its ability to perform tasks that require understanding or analyzing extremely large datasets in a single pass.
The Efficiency of LTM-2-mini
One might assume that handling such a vast amount of data would require proportionally massive computational resources, making it impractical for most applications. However, Magic has ingeniously addressed this concern through a highly efficient sequence-dimension algorithm. This algorithm is approximately 1,000 times more efficient than the attention mechanisms used in models like Llama 3.1.
Traditional models rely on attention mechanisms that become exponentially more resource-intensive as the context window expands. This inefficiency has been a significant roadblock, both in terms of computational cost and energy consumption. Magic's algorithm optimizes the processing by reducing the computational load without sacrificing performance. This means that even with the enormous 100 million token context window, the model remains practical and cost-effective to deploy.
While the technical specifications of LTM-2-mini are impressive, what truly sets it apart is how it changes our approach to problem-solving with AI. This model doesn’t just process more data; it understands data in a more holistic way. By considering a broader context, it can draw connections that were previously inaccessible to machines.
A Deeper Dive into the Sequence-Dimension Algorithm
At the heart of LTM-2-mini’s capability is its innovative sequence-dimension algorithm. Unlike traditional attention mechanisms that become unwieldy with larger datasets, this algorithm scales efficiently, allowing the model to maintain performance without exponential increases in computational resources. This advancement is not just a tweak but a reimagining of how AI models handle information.
The sequence-dimension algorithm works by structuring data in a way that minimizes redundancy and focuses on the most relevant connections. It’s akin to having a conversation where the AI doesn’t just remember what was said a moment ago but retains the entire dialogue, understanding the nuances and subtexts that give meaning to the exchange.
Concerns About Hardware Requirements
One major concern is how LTM-2-mini manages to process such a large context without demanding impractical computational resources. Magic.dev addresses this through their sequence-dimension algorithm, which significantly reduces the computational and memory requirements compared to traditional models. While models like Llama 3.1 would need an enormous amount of hardware, LTM-2-mini requires only a small fraction of a single high-end GPU's capacity.
Overcoming Evaluation Limitations with HashHop
To ensure LTM-2-mini genuinely leverages its expansive context window, Magic.dev developed an innovative evaluation method called HashHop. Unlike traditional evaluation techniques that can be biased by semantic hints or focus on recent information, HashHop uses random, incompressible hash pairs. This approach eliminates semantic cues and requires the model to store and retrieve information from all parts of the context.
Testing Multi-Hop Reasoning
Beyond simple retrieval, HashHop evaluates the model’s ability to perform multi-hop reasoning. By asking the model to complete chains of hashes (e.g., Hash 1 → Hash 2 → Hash 3…), it simulates real-world tasks like variable assignments in code, where multiple pieces of information are connected. This tests the model’s capacity to understand and navigate complex relationships within vast datasets.
Challenging with Skip-Step Tasks
To further assess its capabilities, HashHop introduces skip-step tasks where the model must predict a final hash directly from the first one (e.g., Hash 1 → Hash 6). This challenges the model to jump across multiple points in the context, ensuring it can handle non-linear and complex reasoning tasks.
Transforming Industries
The revolutionary capabilities of LTM-2-mini have the potential to transform various industries, particularly those dealing with large volumes of complex information. Two sectors that stand to benefit significantly are software development and legal document analysis. The impact of this technology in these fields showcases its broader potential to reshape how we handle and process information across numerous domains.
Revolutionizing Software Development
In the realm of software development, LTM-2-mini's ability to process 10 million lines of code simultaneously represents a paradigm shift. Traditional AI coding assistants, constrained by narrow context windows, often struggle to provide comprehensive insights or identify complex dependencies across large codebases. LTM-2-mini overcomes these limitations, offering developers unprecedented support in managing and understanding vast software projects.
The model's comprehensive code analysis capabilities enable it to identify intricate relationships and dependencies across entire codebases. This holistic view allows for optimization suggestions that consider the full scope of a project, leading to more efficient and robust software architectures. By ensuring consistency in coding style, naming conventions, and best practices, LTM-2-mini significantly enhances code quality. It can flag potential bugs and security vulnerabilities by cross-referencing with known issues in similar codebases, providing an additional layer of quality assurance.
LTM-2-mini's impact extends beyond code analysis and quality assurance. By automating routine tasks and providing context-aware suggestions, it accelerates the development process, allowing developers to focus more on innovation and complex problem-solving. The model can generate boilerplate code, write comprehensive unit tests, and even propose algorithms based on high-level descriptions. This not only speeds up development but also reduces the likelihood of human error in repetitive tasks.
The model's deep understanding of codebases also revolutionizes documentation practices. It can generate accurate and comprehensive documentation, including explanations of complex functions, usage examples, and architectural diagrams. This capability greatly improves project maintainability and facilitates knowledge transfer within development teams. Furthermore, LTM-2-mini's ability to perform intelligent code reviews, analyzing pull requests in the context of the entire codebase, enhances collaboration and ensures adherence to project standards and best practices.
Making Legal Document Analysis Smarter
The legal field, which deals with a lot of detailed and complex documents, can greatly benefit from LTM-2-mini. This model analyzes entire legal documents at once, ensuring that no important information is missed, which helps avoid misunderstandings that can come from reading things out of context. This means better and more accurate analysis of contracts, cases, and regulations.
One of the standout features of LTM-2-mini is how it handles large legal databases. It can find relevant cases by understanding legal reasoning and comparing facts, even when the wording is different. This makes legal research faster and helps lawyers build stronger arguments.
LTM-2-mini is also useful for keeping things consistent across multiple documents. It can compare clauses in different contracts or regulations, pointing out inconsistencies that might cause legal problems. This is especially helpful in big deals, like mergers, where reviewing many documents quickly is crucial. The model helps speed up the process while making sure no important details are missed.
Beyond just retrieving information, LTM-2-mini can track changes in legal thinking, spot trends, and suggest new legal approaches. It analyzes laws, rules, and scholarly papers, giving lawyers a powerful tool for crafting new strategies.
Though LTM-2-mini boosts efficiency and reduces errors, it's meant to support—not replace—legal experts. It allows professionals to focus on strategy and complex decisions, potentially improving legal results and access to expert advice.Broader Implications for the Future of AI
Conclusion: Embracing the Future
For me, Magic's LTM-2-mini is more than just a tech breakthrough—it’s a turning point. By breaking through the limits of data processing and context understanding, it opens up opportunities that once seemed out of reach.
As someone who’s deeply invested in this space, I’m genuinely excited by the possibilities it unlocks. LTM-2-mini challenges us to rethink how we use AI and pushes us to explore new applications that can reshape industries and improve everyday life. It’s not just about creating smarter machines—it’s about giving us the freedom to focus on what truly matters: creativity, strategy, and deeper connections.
What makes LTM-2-mini special is how it enhances what we do, helping us move past routine tasks so we can focus on things that make a real difference. It’s not about replacing our work, but about expanding our potential to innovate and achieve more.
Moving forward, it’s crucial that we handle this progress responsibly. By keeping ethics at the core of AI development, we ensure that innovations like LTM-2-mini bring positive change to the world.