
🤓 Latest Submissions
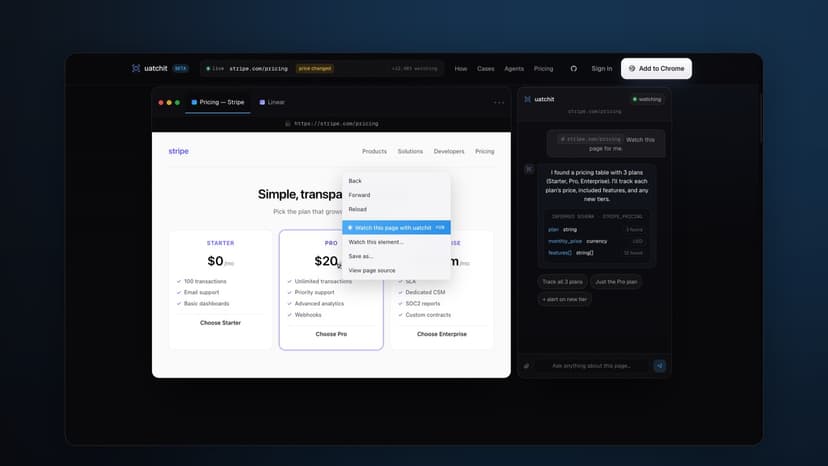
Uatchit: A Chrome Extension That Watches The Web
uatchit is a general purpose web monitoring tool that fits every track, whether you are tracking competitors and pricing for GTM, filings and market data for finance, or CVEs and regulatory pages for security and compliance. It turns any web page into a structured, monitored data source. Right-click a page and an AI side panel opens, where a model reads the page and proposes a schema of the fields worth tracking, like prices, headlines, filing dates, or CVE scores, which you refine in plain English. uatchit then re-fetches on a schedule, diffs each snapshot, and narrates what changed as a sentence, for example: "Claude went from $20 to $25 per month." Bright Data Web Unlocker is the fetch layer, returning clean markdown and getting past bot walls and JavaScript rendering, with Scraping Browser as a fallback, while AIML API runs the Gemini models that infer the schema, extract values, and write the narration. Every watch is also an MCP feed, so the same diff that emails a human is available to Claude Desktop, Cursor, or any agent. uatchit is live and in open beta as a Chrome extension plus a Next.js web app.
31 May 2026

CyberSecQwen-4B: CTI Specialist Fine-tuned on AMD
CyberSecQwen-4B is a 4B-parameter cybersecurity language model fine-tuned from Qwen3-4B-Instruct-2507 and trained end-to-end on a single AMD Instinct MI300X 192 GB instance. The entire pipeline, including corpus assembly, LoRA fine-tuning, adapter merging, and evaluation, was completed on a single GPU. Under the published evaluation protocol for Cisco Foundation-Sec-8B (arXiv:2504.21039), CyberSecQwen-4B scores 0.5868 on CTI-MCQ and 0.6664 on CTI-RCM based on 5-trial means at temperature 0.3. It exceeds Foundation-Sec-Instruct-8B on CTI-MCQ by +8.7 points at half the parameter count while staying within 1.9 points on CTI-RCM, with all metrics measured using our own harness under the same protocol. The AMD MI300X stack performed excellently throughout. FlashAttention-2 was enabled during training because Qwen3-4B's 128-dimensional attention heads fit within the gfx942 LDS budget, delivering a 1.6× step-time speedup over sdpa. The pipeline runs inside the official vllm/vllm-openai-rocm Docker image with AITER kernels and HipBLASLt enabled. Upload speed was also efficient, as the 8 GB merged model reaches Hugging Face in approximately 36 seconds at ~240 MB/s via the AMD Developer Cloud link. Key methodological highlights include: 1. Decontaminated training data: An earlier internal run showed 72% test-set overlap in undeduplicated CTI corpora, so the released model trains exclusively on the 2021 CVE→CWE cohort with CTI-Bench overlap removed. 2. Direct SFT: This approach outperformed knowledge distillation from a 20B teacher at the current corpus scale. 3. Multi-trial reporting: Results include standard deviations rather than single-trial numbers. Recipe portability was validated by applying the same corpus and hyperparameters to a second model family, Gemma-4-E2B-it. Both models converge within 0.9 points on CTI-RCM (0.6664 Qwen vs 0.6754 Gemma), providing strong evidence that the result is recipe-driven rather than substrate-specific.
10 May 2026



