🤓 Latest Submissions
Bob Skills Registry
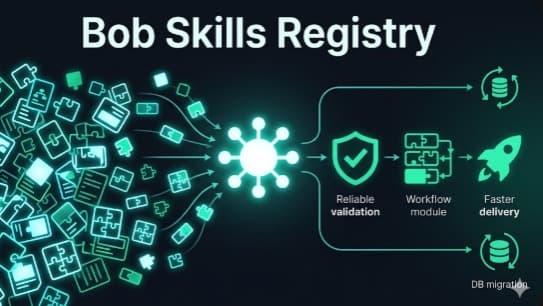
`Bob Skills Registry is a solo-built workflow reuse system for IBM Bob. The core problem it solves is repeated prompt engineering: teams keep rebuilding the same multi-step Bob flows across projects, which wastes time and produces inconsistent results. This project introduces a portable skill format plus a CLI that makes proven Bob workflows discoverable, installable, and repeatable. A skill is defined as structured JSON with parameters, ordered steps, and context references. The registry indexes skills, and the CLI provides practical commands to use them: list available skills, install skills locally, inspect installed skills, run workflows in interactive or non-interactive mode, and validate registry consistency. Validation is a key part of the design: schema checks and custom guardrails prevent weak skills by enforcing parameter integrity, placeholder correctness, and context format quality. The project includes two real skills: API test generation with auth-aware prompts, and database migration generation with up/down expectations. A demo TypeScript project is included to verify outcomes, along with root CLI tests and demo tests that prove reliability. Most importantly, this submission demonstrates meaningful IBM Bob usage as the core development partner: from feature design and iterative implementation to debugging, validation hardening, and test expansion. The result is a practical productivity multiplier that helps developers execute complex Bob workflows consistently instead of starting from scratch every time.`
17 May 2026
ReplayLab: GPU Experiment Flight Recorder
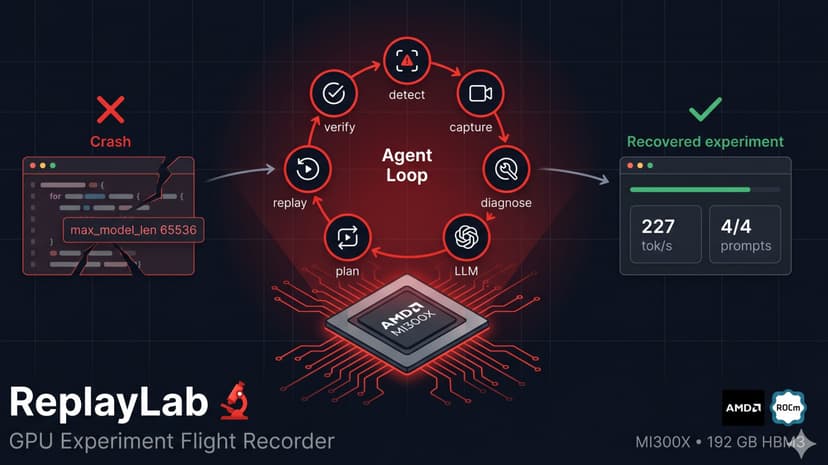
ReplayLab is an autonomous recovery agent for GPU experiments. When a vLLM serving job crashes on AMD Instinct MI300X — whether from memory pressure, context length violations, or timeout failures — ReplayLab detects the failure, diagnoses the root cause, generates a targeted fix, and replays the corrected experiment. No human in the loop. The agent runs an eight-step closed loop: detect failure, capture evidence (logs, config, GPU telemetry via rocm-smi), classify against a 10-pattern vLLM/ROCm failure taxonomy, run LLM-powered diagnosis using Qwen2.5-7B-Instruct served by vLLM on the same MI300X, plan a minimum parameter change, replay the experiment, and verify recovery. Real MI300X benchmarks: 227 tok/sec sustained throughput, 2,931 tok/sec aggregate at 16x concurrency, 604ms LLM diagnosis latency, and sub-second time-to-first-token — all on a single MI300X with 192 GB HBM3, ROCm 7.2.0, and vLLM 0.17.1. We chose a 7B model deliberately: diagnostic agents need speed, not scale. Qwen 7B fits in 14 GB, runs at full float16 precision with no quantization, and leaves 155 GB free for the workloads being diagnosed. Each recovery cycle costs $0.14 in GPU time, compared to ~$150 and 2 hours of manual debugging. That's 1,071x cheaper and 28x faster. Every recovery produces a structured evidence trail — before/after metrics, GPU memory snapshots, LLM diagnosis, and full agent reasoning trace — giving engineers an auditable record they can trust and reproduce. Open source, MIT licensed, 38 tests passing. Built for Track 1: AI Agents & Agentic Workflows.
10 May 2026

