.png&w=256&q=75)
🤓 Latest Submissions
ROCmBench Agent
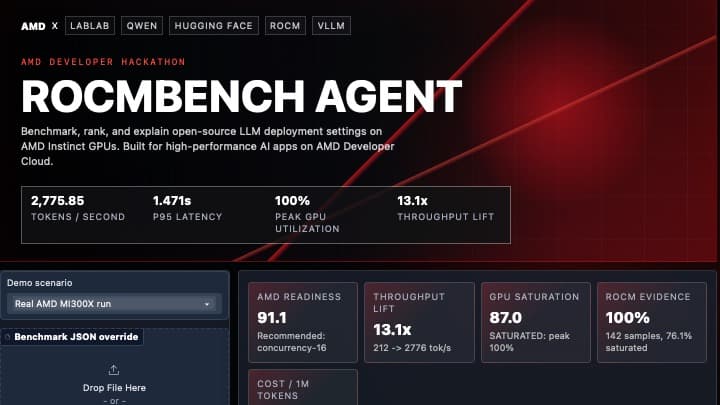
ROCmBench Agent is an AMD GPU deployment copilot for open-source LLMs. Instead of only checking whether a model runs, ROCmBench answers the harder production question: which configuration should actually be deployed? The app lets users select a Hugging Face model, auto-load it on an AMD Developer Cloud GPU using vLLM + ROCm, run concurrency sweeps, collect ROCm SMI GPU evidence, and generate a deployment decision. It scores each serving configuration across throughput, p95 latency, error rate, cost per 1M tokens, VRAM pressure, and GPU saturation. The project includes real AMD MI300X benchmark results for Qwen2.5-7B, Qwen2.5-3B, long-context tests, and soak-style stability checks. One key finding was that Qwen2.5-7B at concurrency 24 was a better production config than concurrency 32: concurrency 32 had only a tiny throughput gain, but p95 latency nearly doubled. ROCmBench produces a deploy / warn / block decision, a recommended vLLM launch command, ROCm proof, cost estimates, a production gate matrix, and a generated deployment report. The goal is to turn AMD GPU benchmarking into a repeatable deployment workflow instead of a one-off experiment.
10 May 2026

