
🤓 Latest Submissions
Riprap: Agentic Flood Risk Intelligence for NYC
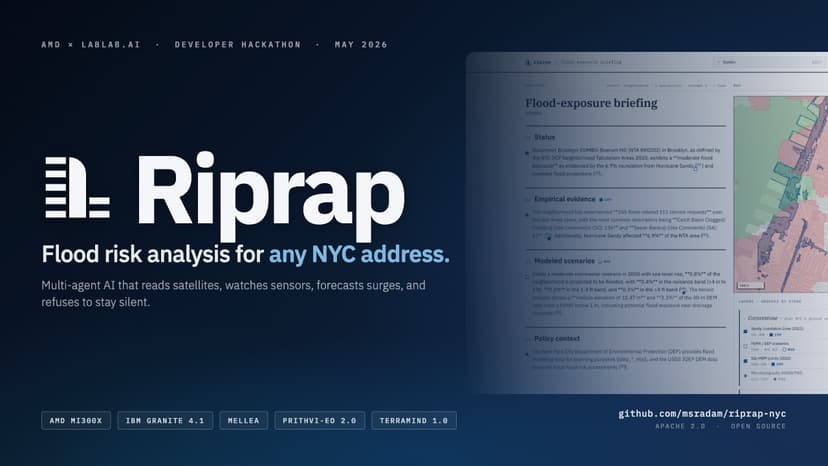
Riprap turns any NYC address into a citation-grounded flood-exposure briefing in about two minutes. Every claim points back to a [doc_id] in public-record data. No vendor scores, no opaque aggregators. The problem: NYC has spent decades publishing the inputs (Sandy 2012, DEP stormwater, FloodNet, NOAA tides, USGS LiDAR, 311, MTA, NYCHA, schools, hospitals). The data is public. None of it composes itself. Every engineer reassembles the same evidence by hand, per address, from a dozen agencies. Riprap composes it. Three NYC-specialised foundation-model fine-tunes shipped Apache 2.0, trained on a single AMD MI300X via AMD Developer Cloud: TerraMind-NYC-Adapters: LULC mIoU 0.5866 (huggingface.co/msradam/TerraMind-NYC-Adapters) Prithvi-EO-2.0-NYC-Pluvial: flood IoU 0.5979 vs 0.10 on Sen1Floods11 base, 6x lift (huggingface.co/msradam/Prithvi-EO-2.0-NYC-Pluvial) Granite-TTM-r2-Battery-Surge: NYC Battery surge nowcast, MAE 0.109 m, 41% better than persistence (huggingface.co/msradam/Granite-TTM-r2-Battery-Surge) About 25 atomic data probes fan out, organised as the Five Stones: Cornerstone (hazard memory), Keystone (asset registers), Touchstone (live state), Lodestone (forecasts), Capstone (citation-grounded synthesis). The Five Stones taxonomy is city-agnostic. Only the probes plugged into each Stone change. To port Riprap to another flood-vulnerable region, you reimplement each Stone's collect() against local data and retrain the EO and time-series fine-tunes on the jurisdiction's imagery and tide gauges. The agentic shell stays the same. The pipeline is a Burr FSM with one @action per probe; Mellea rejection sampling re-rolls until four grounding checks pass. Inference runs through a LiteLLM Router targeting either AMD MI300X (vLLM, BF16 Granite 4.1 8B) or NVIDIA L4 (vLLM, FP8 Granite 4.1 8B) co-resident with the EO model stack. Full architecture, methodology, and licence map: github.com/msradam/riprap-nyc
10 May 2026
