🤝 Top Collaborators


🤓 Latest Submissions
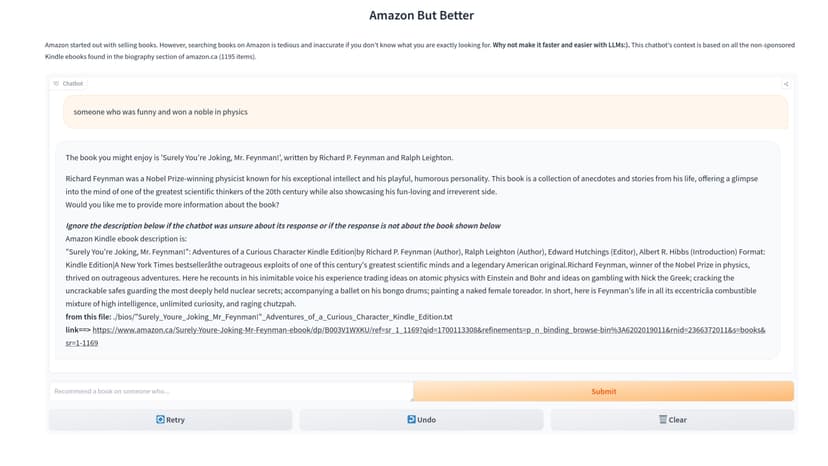
Amazon-But-Better
## Intro Amazon started out with selling books. However, searching books on Amazon is tedious and inaccurate if you don't know what you are exactly looking for. **Why not make it faster and easier with LLMs:)**. This chatbot's context is based on all the non-sponsored Kindle ebooks found in the biography section of amazon.ca (1195 items). **check out the FREE chatbot here:** https://huggingface.co/spaces/mehrdad-es/Amazon-But-Better ## Strategy 1. Gather Kindle Ebook Descriptions using selenium 2. Create Embeddings Dataset with Cohere embed and Chromadb 3. Use Langchain RetrievalQA & Cohere Command to query this the ebooks vector embeddings dataset ## Notes * Experimenation with memory and ConversationRetrievalChain has resulted in less performance, usefulness, and more halucination. Hence, this chat bot provides one shot answers with zero memory. You can use the code in the RAG notebook to do this experimentation.
18 Nov 2023
.png&w=828&q=75)
Summarize Legal Legislation Fintuned Model
StableLM-tuned-alpha-3b was finetuned with lit-gpt repo lora method. This performed considerably better then the original model. Subject Matter ROUGH score for chatgpt summarization is 8/10 Subject Matter ROUGH score for legalLLM is 3/10 Subject Matter ROUGH score for stableLM-tuned-alpha-3b is 0/10 Considering gpt3 was 175B and chatgpt is most likely bigger, the fact that legalLLM could score 3 is significant Training was done with lighteval/legal-summarization dataset. look at attached github repo for fine-tunning parameters. This fintuned model is uploaded huggingface under mehrdad-es/legalLLM-hf The github repo shows how to create your gradio app to chat with the model. It is recommended to get a10 46GB ram system.
10 Nov 2023

Talk to Legislation- New Jersey State Title 15A
We uses langchain, chatgpt, and frontend deployment to create a RAG chatbot which answers questions based on 171 documents. The prompt template is set up to provide an answer to users question along with the subsection the answer was found in. The prompt also includes saying I don't know if it's not sure. Langchain memory was also used to have continuous conversation with the user. In addition we tested chatgpt4, cohere RAG, bingchat to test out how other solutions performed. With the help of our legal expert we had these observations: * All tested language model aren't good enough to perform high accuracy RAG * Sometimes a model hallucinated a quote and sometimes it completely misunderstood the question or the legislation. GPT4 mentioned a certain document had a quote when in fact it didn't. When confronted, gpt4 made up a reason as to why it said something existed when it fact it didn't. * Cohere solution was very neat in that it provided hyperlinks to documents it was quoting on. Yet it made up stuff or did not understand the content of documents properly * bingchat overall performed better than gpt4 and cohere RAG but still hallucinated or misunderstand the legislation. Hence we created custom chatbot. Feel free to use it and provide feedback. We did check legal LLMs on huggingface although there were not chat legal LLMs and most of the legal models were fill-mask. We do believe the best solution would be a fine-tuned legal LLM based on a large legal dataset. Data is title 15A of New Jersey law downloaded from justia.com with selenium. 171 individual documents are the sub-sections of title 15A. (https://law.justia.com/codes/new-jersey/2022/title-15a/)
25 Oct 2023


