

Rick Holmberg@juiceb0xc0de
3
Events attended
1
Submissions made
Canada
1 year of experience
About me
A year ago I left bartending with an AI model and a Comp Sci dream and I've been speed running everything related ever since. When I quit a 10 year career in the restaurant industry I didn't know what a terminal was and thought python was an adjective reserved for snakes. I've spent over 5000 hours learning everything from kernel behaviour, cyber security and machine learning. I trained my first LLM on January 2, 2026 and I haven't looked back since. I'm on the pursuit of a perfect model (never gonna find it). I'm interested in creating a training method that solves semantic redundancy between layers after fine-tuning models. I'm designing new schedulers for fine-tuning. I train models on datasets I've curated and am testing a single voice corpus I made by taking my own conversations with AI models and flipping the script. The model became the user and I am the assistant. I love creating new training methods or finding ways to solve real problems. I break things and then put them back together in a novel ways. I may not have a lot of years of experience behind me but I am by no means new to the concepts of Comp Sci. I understand systems in a unique way backed by a life experience working in systems unrelated to tech. I used life experience to port TCP packets into a VM without the need for a USB WiFi adapter or dongle. A problem that people say can't be solved is just a puzzle that hasn't been put together yet.
🤓 Latest Submissions
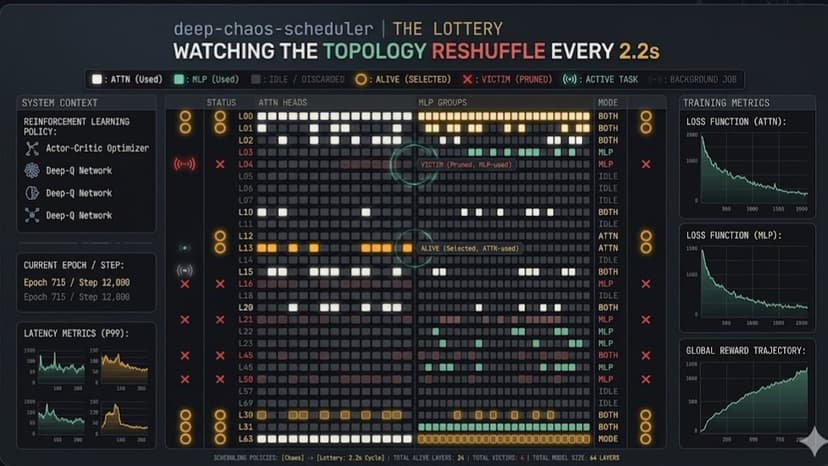
Deep Chaos Scheduler with kernel optimization
The Deep Chaos Scheduler picks which layers train during full fine-tuning instead of training all of them. The hypothesis: full fine-tuning isn't always necessary for a model to learn things like math — the parameters that need to update don't have to be contiguous, and randomly-located subsets can match or beat the dense baseline.Every 50 training steps — what I call a sticky block — the scheduler designates 30 to 70% of the victim layers as active for that block. Active victims are then narrowed further at random into one of four modes: full (both attention and MLP), attention only, MLP only, or skipped entirely. Within active attention heads and MLP channels, 30 to 70% are kept; within hidden dimensions, 60 to 95% are kept. The unselected 50 steps' worth of parameters and activations don't just get masked — a custom kernel optimization called the layer hoist physically yanks dead and identity layers out of model.layers before the forward pass, and drops a tiny frozen residual stub in their place so the surviving layers don't suddenly receive the previous surviving layer's output verbatim. The forward graph shrinks for the whole block, training runs 2.25x faster wall-clock and uses 18% less VRAM on a 5-epoch Qwen2.5-3B run on MI300X, and the math gradients flow through a different random sub-network every 50 steps.Benchmarked against a true full fine-tune on the same data (simplescaling/s1K), same compute budget, three independent random seeds, using LM Evaluation Harness on GSM8K, Minerva Math, MATH-500, and MGSM. At 3B, DeepChaos beat the FFT-3B baseline by +17.2pp on MGSM, and DeepChaos-3B outperformed FFT-7B on MATH-500 despite being half the size. At 7B, every chaos seed beat the dense baseline across every Minerva subcategory, with gains up to +13.2pp on prealgebra and +8.6pp on overall Minerva math_verify. Three-seed consistency rules out lucky-mask explanations.
10 May 2026


