

Mohit Madan@icyzh
3
Events attended
2
Submissions made
India
2+ years of experience
About me
Hi, I'm someone who genuinely enjoys building things and figuring out how they work. Most of my time is spent coding, experimenting with AI, working on full-stack projects, and exploring GPU programming. I love taking an idea that exists only as a random thought and turning it into something people can actually use. When I'm not building, I'm usually learning about new technologies, contributing to open source, joining hackathons, or going down a rabbit hole on a topic that caught my interest. I'm always happy to connect with people who enjoy creating, learning, and solving interesting problems.
🤝 Top Collaborators
.png&w=640&q=75)
🤓 Latest Submissions
.png&w=828&q=75)
Ghost of Curie
Ghost of Curie is a production-ready, autonomous logistics and compliance platform designed for the complex, time-sensitive coordination of radioligand diagnostics and therapeutics (such as Lutetium-177 and Fluorine-18). Because nuclear medicines have a high rate of radioactive decay, delays during transport can render patient doses unviable, leading to severe treatment disruption and waste. The platform addresses this challenge through three main pillars: - Dynamic Decay Physics Engine: Performs real-time radioactive decay calculations based on the half-life of isotopes. The system calculates the projected millicuries (mCi) at the time of delivery against specified clinical safety thresholds. - Multi-Agent Collaboration Loop: Integrates with Band.ai WebSockets to orchestrate a collaborative chat room where AI specialist agents; including Physicists, Pharmacists, and Logistics Coordinators—discuss delay alerts, verify target facilities, and propose rerouting. - Enterprise Compliance & Auditing: Automatically verifies medical facilities against NRC database registries. The system records all transitions, physics calculations, and agent discussions into immutable JSONL audit logs and session summaries, providing a transparent chain of custody. - Built as a modern web application, it combines a fast FastAPI backend utilizing Pydantic for schema validations and local database serialization with a premium React/Vite/TypeScript frontend dashboard featuring responsive glassmorphic cards and interactive simulation controls.
19 Jun 2026
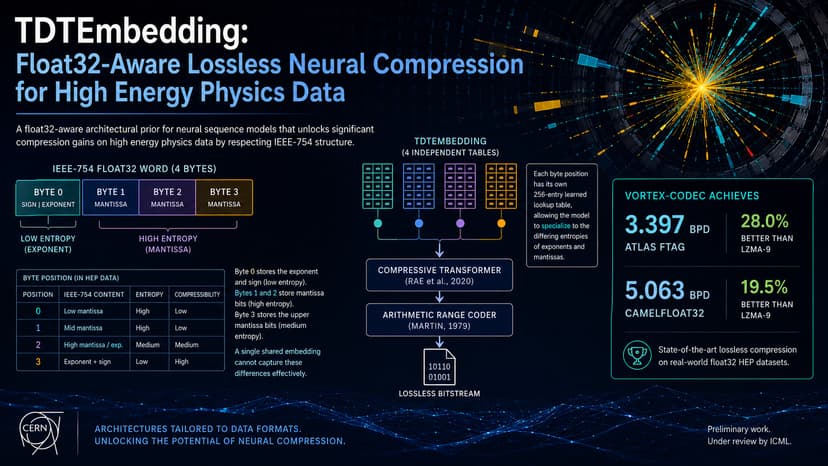
Vortex Compressor Float32 Compression
High Energy Physics (HEP) experiments produce massive amounts of detector data, generating around 15 PB per year. Storage capacity already constrains what can be retained long-term. Current pipelines rely on standard lossless compressors (like LZMA) that treat IEEE-754 float32 byte streams as unstructured data, ignoring the internal structural heterogeneity of floating-point formats. To solve this, we introduce Vortex Codec, featuring a novel architectural prior called TDTEmbedding (Type-Decomposed Token Embedding). Instead of a single shared lookup table, TDTEmbedding maintains four independent tables indexed by byte position modulo 4. This allows the neural sequence model to learn specialized representations for low-entropy exponent bytes and high-entropy mantissa bytes from scratch. We integrated this with a Compressive Transformer using Learnable Token Eviction (LTE) and an arithmetic range coder. Our 87M parameter model was trained and profiled using an MI300X GPU on the AMD Developer Cloud. The results establish state of the art archival efficiency: Vortex Codec achieves 3.397 and 5.063 bits-per-byte (BPD) on the ATLAS FTAG and CamelFloat32 benchmarks, representing a 28.0% and 19.5% improvement over LZMA-9.
10 May 2026


