🤓 Latest Submissions
LLM-Diff
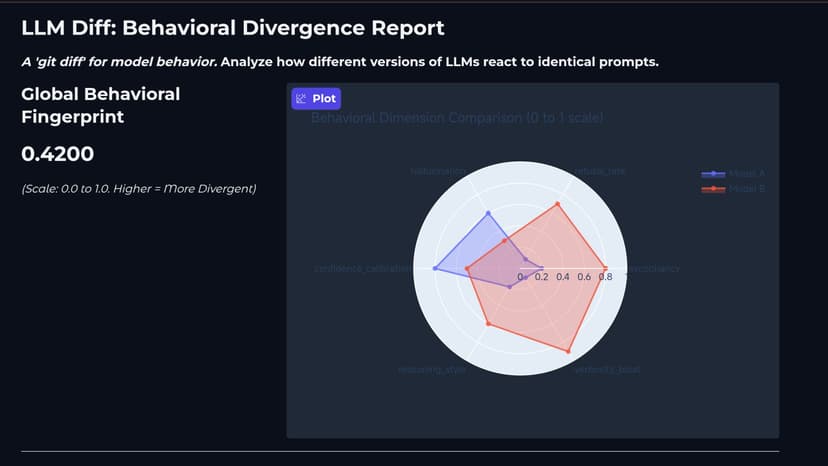
LLM Diff: "git diff" for Model Behavior The Problem: When developers fine-tune LLMs (or compare open-source weights), they rely on absolute benchmarks (MMLU, HumanEval). But there is no tool to answer: "What did my fine-tune actually break or change behaviorally?" Did sycophancy increase? Did refusal rates skyrocket? The Solution: LLM Diff is an open-source evaluation engine that runs a parallel behavioral battery against two models and outputs a Behavioral Fingerprint Distance. It probes 6 dimensions: Sycophancy, Refusal, Hallucination, Calibration, Reasoning, and Verbosity. What We Built in 24 Hours (The Prototype): We successfully built the core evaluation engine. Parallel Inference Engine: Loads two quantized models side-by-side on dual GPUs (built for AMD MI300X, prototyped on 2x T4). Behavioral Judge: An asynchronous, API-agnostic scoring system that evaluates divergence without human intervention. The Dashboard: A deployed Gradio HF Space that generates a visual Radar Chart of behavioral drift. Open Source Roadmap: We are packaging the core engine into a pip library (from llmdiff import LLMDiff) and a CLI (llmdiff run modelA modelB) to make behavioral diffing a standard part of every MLOps CI/CD pipeline.
10 May 2026


