🤓 Latest Submissions
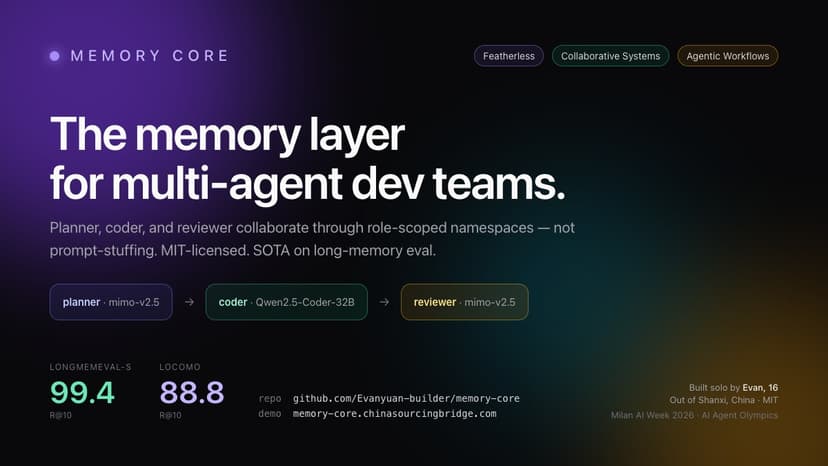
Memory Core: Role-Aware Memory for Agent Teams
Multi-agent dev teams have a coordination problem disguised as a memory problem. When planner, coder, and reviewer agents collaborate today, they pass context through prompts — concatenating each other's outputs, paying for every re-injected token, losing the thread on every session reset. The framing that the model is the substrate is wrong. The memory layer is. Memory Core makes context a first-class shared resource — every agent reads the role-scoped slice it needs, nothing else. For Milan AI Week we built a three-agent dev team — planner, coder, reviewer — collaborating on a real coding task ("add a dark-mode toggle to a Next.js settings page") through Memory Core's namespaces. The planner (mimo-v2.5) writes a multi-step plan. The coder (Qwen2.5-Coder-32B-Instruct via Featherless) reads planner + bootstrap, emits [FILE] blocks, stores each as an artifact. The reviewer (mimo-v2.5) reads planner + coder, writes a critique.Each agent sees only its own role's prompt. Featherless track fit: domain-specialized (software dev teams), async-first (namespaces, not chat turns), permissive (MIT core + Apache-2.0 eval),v1.0.0). Benchmarks (reproduction in memory-core-eval, Apache-2.0): - LongMemEval-S R@10 = 99.4 (anchor: 97.9) - LoCoMo R@10 = 88.8 (anchor: 85.0) Cross-restart determinism verified. Stack: FastAPI + LanceDB + optional MCP adapter; hybrid dense+sparse retrieval with RRF fusion and cross-encoder rerank; role_scope filter pushed down into LanceDB SQL. Built solo by Evan (16) out of Shanxi, China. Memory Core is the flagship of an open-source substrate stack alongside temporal-core, RoleCore, and EvanCore. Live demo: https://memory-core.chinasourcingbridge.com GitHub (MIT): https://github.com/Evanyuan-builder/memory-core Eval (Apache-2.0): https://github.com/Evanyuan-builder/memory-core-eval
19 May 2026
