.png&w=256&q=75)
🤓 Latest Submissions
Nexus: The Autonomous AMD FinOps Agent
Startups and enterprises are stuck paying a premium for legacy NVIDIA infrastructure because evaluating a migration to AMD ROCm feels risky, technical, and time-consuming. Nexus removes that barrier by turning migration analysis into an automated, auditable process instead of a guessing game. You give Nexus a real Dockerfile or requirements.txt. It parses every dependency and checks it against a hand-verified knowledge graph of CUDA-to-ROCm migration rules — not a vector search, not an LLM hallucination, an actual deterministic lookup table built from real compatibility data. Gemma 4, called via Fireworks AI on AMD-hosted infrastructure, acts as the reasoning and presentation layer on top of that ground truth: using native function calling, it's constrained to only explain and format mappings that exist in the verified ruleset, never invent one. Every dependency in the report gets a color-coded confidence score: green for a direct, verified port; yellow for a functional equivalent with minor behavioral differences; red for "manual verification required," where no safe automated mapping exists. This is a deliberate design choice — Nexus is built to say "I don't know" instead of confidently guessing, which is the difference between a tool teams can actually trust and a demo that falls apart under scrutiny. Cost savings are never estimated by the LLM either. Nexus calculates them in plain Python from a sourced, dated pricing table comparing current NVIDIA instance rates against equivalent AMD MI300X pricing, so every number in the report is auditable back to its source. The result is a clean Streamlit dashboard: paste your current setup on the left, get a full migration report on the right — confidence-scored dependency table, real cost comparison, and a ready-to-use ROCm Dockerfile. Nexus is effectively an AI sales engineer for AMD, but one that earns trust by showing its work instead of just making claims.
13 Jul 2026
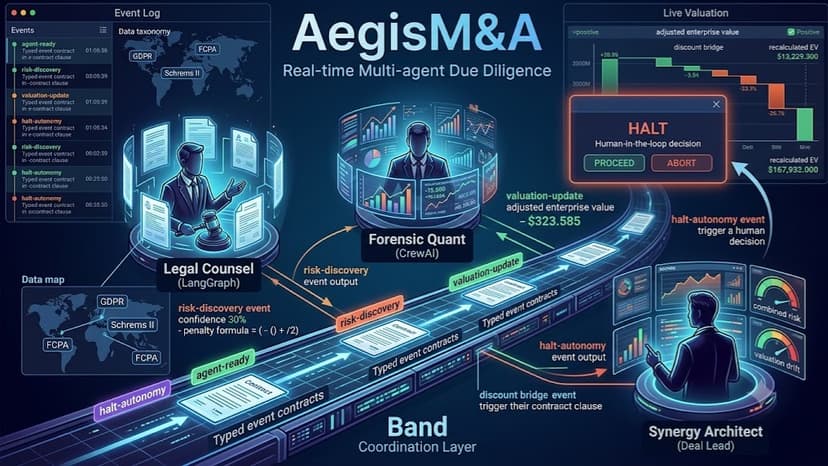
Aegis M&A
AegisM&A is a multi-agent due-diligence system that coordinates three specialized agents through Band to analyze M&A deals in real time. Legal Counsel (built on LangGraph) reads target-company contracts and maps clauses against a regulatory taxonomy — GDPR, Schrems II, FCPA — assigning each finding a real penalty formula and confidence score. Forensic Quant (built on CrewAI) holds the live valuation model and recalculates the deal's adjusted enterprise value the instant a new risk lands in the shared Band room, producing a full traceable discount bridge back to the originating clause. Synergy Architect is the deal lead: it watches both agents, scores combined risk and valuation drift against hard thresholds, and when those thresholds breach, halts autonomous execution and escalates to a human reviewer through the dashboard. The core insight is that none of this works inside a single framework. LangGraph and CrewAI don't share state by default — Band is the coordination layer that lets a LangGraph agent's legal finding instantly trigger a CrewAI agent's valuation recalculation, instantly trigger a halt decision, without any agent needing to know how the others are built. Every agent broadcasts through the same typed event contract — agent-ready, risk-discovery, valuation-update, halt-autonomy, human-decision — so coordination happens through structured state, not free-text chat. The dashboard renders this live: a split-screen event log and valuation panel, with a HALT modal exposing PROCEED/ABORT controls that close the human-in-the-loop decision back into the same Band room the agents are watching.
19 Jun 2026
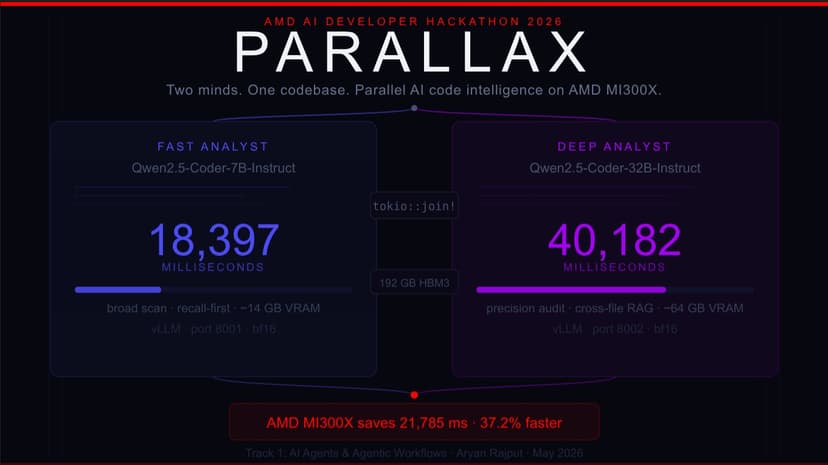
Parallax
ROCm was the enabling layer for the entire project. Setting up vLLM on ROCm 6.x was significantly smoother than anticipated — gpu-memory-utilization flags worked correctly, bfloat16 precision loaded cleanly on MI300X, and both models (0.12 + 0.55 = 0.67 utilization) coexisted without conflict. The 192 GB unified pool made it trivial to set explicit VRAM budgets per model without worrying about fragmentation. One friction point: ROCm's documentation for multi-model concurrent serving with vLLM could be more explicit. I had to empirically discover the safe utilization ceiling rather than find it in the docs. AMD Developer Cloud provided low-latency access to MI300X hardware with no cold-start surprises. Provisioning was fast, SSH access was reliable, and the hardware behaved exactly as the specs suggested — the full 192 GB was addressable and stable under sustained dual-model inference load. The benchmark numbers in the README (18,397 ms / 40,182 ms) are real, captured live on the Cloud instance. A persistent storage option (beyond the session) and a simple web dashboard for monitoring live GPU utilization would make it significantly easier to iterate during a hackathon. AMD APIs / vLLM + ROCm: The OpenAI-compatible /v1/chat/completions endpoint that vLLM exposes on ROCm worked perfectly with standard Python httpx clients — zero code changes needed compared to CUDA-based setups. Prometheus metrics (/metrics) exported by the Rust engine confirmed consistent GPU throughput across both model instances. Overall the developer experience was solid; the main ask is better first-party documentation specifically for concurrent multi-model deployments, which is the exact use case that makes AMD hardware uniquely powerful.
10 May 2026



