.png&w=256&q=75)
🤝 Top Collaborators
.png&w=640&q=75)
🤓 Latest Submissions
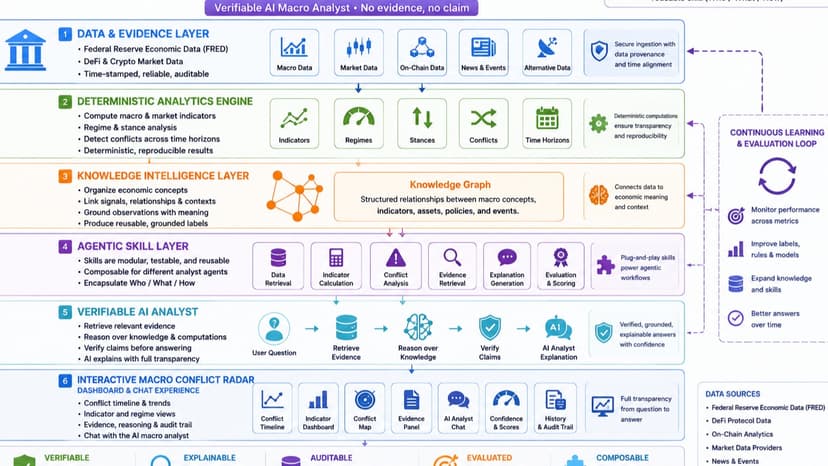
Macro Conflict Radar: An Agentic Skill Platform
Crypto markets are influenced by many macro forces at the same time. Liquidity can appear risk-on while interest rates, the dollar, inflation, or volatility indicate risk-off. Traditional dashboards show these indicators separately, and generic AI assistants explain them without reliably proving where their conclusions came from. Macro Conflict Radar identifies these disagreements and turns them into verifiable macro intelligence. The architecture deliberately separates computation from judgment. Finance algorithms compute indicators and conflicts. The knowledge layer connects those results to economic concepts. Agentic skills then assemble the appropriate evidence and reasoning path for each question. The LLM narrates the result only after the claims have been checked. The platform converts raw macro observations into reusable, evidence-backed intelligence objects.
13 Jul 2026

M3I: Where Does a Small LLM Fail, Layer-Wise?
**M3I — Targeted LoRA-DPO via Multi-Observer Attribution** When small LLMs fail at multi-step reasoning, the errors rarely spread uniformly — specific layers carry the failure. Standard LoRA is blind to this. M3I asks: can two LLM observers identify those layers, then train LoRA-DPO on only them? Five-phase pipeline, validated end-to-end on DeepSeek-V2-Lite (16B MoE): 1. Inference + per-layer signal capture via custom ggml hook 2. Cross-observer audit (Claude Sonnet 4.5 + Gemini 2.5 Pro), agreement required 3. Statistical attribution: paired t-tests at failure vs control tokens, Bonferroni-corrected 4. LoRA-DPO on attribution-identified layers only 5. Held-out eval: verdict + position-bias-controlled pairwise **Status (May 10, 2026):** Trained on 78 problems (50 PhD-level math + 28 crypto microstructure), 116 preference pairs, 3 epochs. Attribution flagged layers {6, 7, 8, 10, 13} — strongest signals at L13 attn (Z=+3.71), L10 attn (Z=+3.13), L6 MoE (Z=-2.84). Held-out eval on 12 problems: base 3 / LoRA 1 / tie 8 in pairwise wins. Three problems shift "incorrect" → "insufficient" — behavioral change without quality gain. Net: null to slightly negative. **Caveats:** n=12 held-out is small; ~20% adapter capacity stripped for GGUF conversion (kv_b_proj / MLA incompatibility); 116 pairs is modest; 16B is below capability floor for these problems. **Next:** (a) random-layer control to separate "attribution fails" from "any DPO at this scale fails"; (b) seed sensitivity for error bars. ~90 min MI300X compute + ~$2 API spend → defensible methodology paper either way. Inference: AMD MI300X via llama.cpp with HIP backend, ~115 t/s with adapter.
10 May 2026



