.png&w=256&q=75)
🤓 Latest Submissions
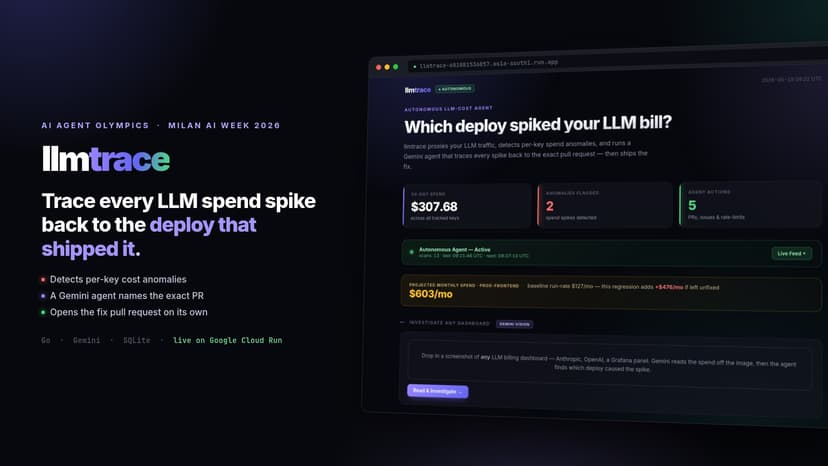
llmtrace: which deploy spiked your LLM bill
Every team shipping AI features eventually asks the same question: why did our LLM bill double last week, and what shipped that caused it? Tools like Helicone, Langfuse, and LiteLLM show you that spend went up. They do not tell you why, llmtrace closes that gap. llmtrace is a self-hosted reverse proxy for LLM provider APIs. You point your code at it instead of api.anthropic.com, and it records token usage, cost, latency, model, and a prompt fingerprint for every call into a local SQLite ledger. A rolling baseline plus sigma threshold flags per-key spend anomalies the moment they appear. When a spike is detected, a Gemini-powered agent takes over. It queries the ledger, finds deploys that landed in the surrounding time window, diffs the model and prompt mix before and after each one, and produces a causal attribution with a confidence score. It names the exact pull request responsible. If the regression is clear, the agent reads the source on GitHub, writes a corrected version, and opens a fix pull request on its own. An autonomous watcher runs this loop continuously in the background, so attributions and remediation pull requests appear without anyone asking. A multimodal Vision Import feature lets you drop in a screenshot of any billing dashboard: Gemini reads the spend off the image, then the agent investigates your connected repository to find the cause. llmtrace is written in Go, uses pure Go SQLite with no CGo, runs as a single container, and is deployed live on Google Cloud Run. The whole thing is one binary you can host yourself, with zero hosted SaaS dependency.
19 May 2026

BrainConnect - ASD
Getting an autism diagnosis takes years. Families wait while kids miss the window where early support matters most. BrainConnect cuts that wait by analyzing brain scans and flagging signs of ASD in under a second. The hard part isn't the AI — it's making it work across hospitals. Brain scanners at different sites produce slightly different data, and most models fail the moment they see a new scanner. We fixed this by training four models, each blind to one hospital's data, then letting them vote at prediction time. If they agree on a scan none of them trained on, the pattern is real. This hit 78.7% accuracy across 529 unseen patients. The AMD MI300X ran our language model fine-tune 4.5x faster than an A100 — turning raw predictions into plain-English clinical summaries a doctor can actually hand to a family. The system also shows which brain connections drove each prediction on a 3D brain map, so clinicians aren't just trusting a black box. Supports multiple brain atlas formats so it works with however your hospital preprocessed the data. Upload a scan on Hugging Face Spaces, get a verdict in under a second.
10 May 2026




