
🤓 Latest Submissions
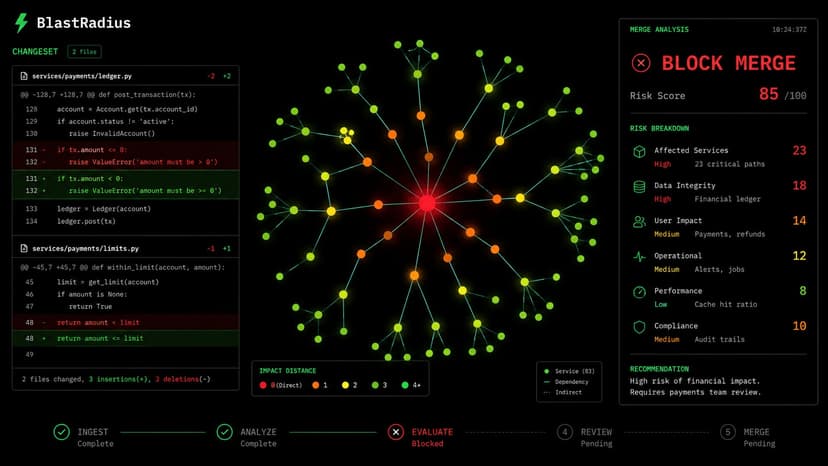
BlastRadius — PR Impact Analysis
Paste a GitHub PR URL. BlastRadius fetches the diff, loads the repository, and runs a two-stage reasoning pipeline powered by IBM Bob. Stage 1 — TraceAgent sends Bob the full priority-ranked repository context with a mandatory chain-of-thought reasoning block. Bob traces every transitive call chain from the changed symbols outward, up to 5 hops deep, assigning risk levels and confidence scores. Each edge is then statically verified using Python AST analysis or JavaScript regex matching and labeled VERIFIED, INFERRED, or UNVERIFIABLE. Stage 2 — RemediationAgent takes every CRITICAL chain with no test coverage and sends Bob a focused second call. Bob generates a complete runnable test stub for each gap plus a one-sentence fix summary. If the verdict is BLOCK, the system computes an estimated incident cost using DORA 2023 benchmark figures and shows it in the UI. The pipeline streams live stage events over SSE so engineers watch the reasoning happen in real time. The final report renders as a D3 force-directed graph — nodes are files, edges are call relationships, colors encode risk, dashed borders mean missing test coverage. Every report gets a shareable URL that survives server restarts via on-disk persistence. IBM Bob was used across five documented sessions during development — improving the prompt engineering strategy, adding TypeScript interface detection, validating AST edge cases, generating additional test cases, and hardening the GitHub Actions workflow. All sessions are exported and committed with verifiable commit references. A GitHub Actions bot posts an automatic impact report as a PR comment on every pull request, making blast radius analysis part of the standard review workflow.
17 May 2026
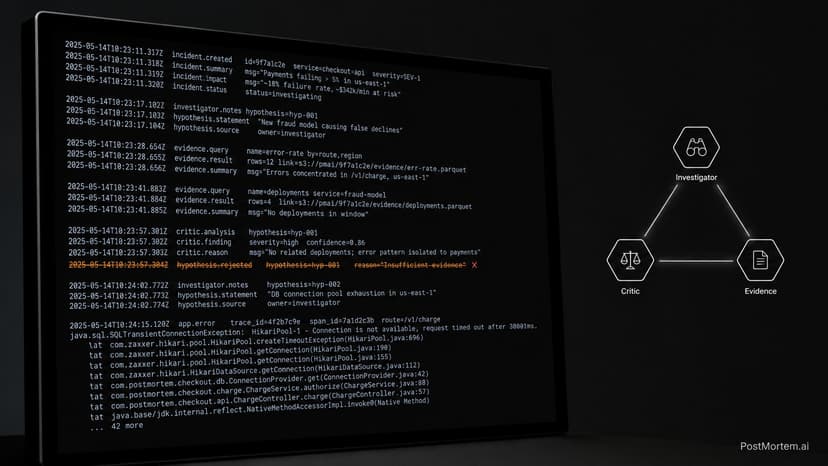
PostMortem.ai: Autonomous Incident Investigation
Production incidents are expensive twice. Once in downtime. Once in the hours engineers spend chasing the wrong lead before finding the real one. PostMortem.ai eliminates the second cost. Feed it an incident ID. Six specialist agents run in sequence, each on a different model sized for its job. Every reasoning step streams live to a terminal dashboard. You get a complete post-mortem with zero human intervention. HypothesisAgent on Llama-3.1-70b (Vultr Serverless Inference) generates investigation leads. EvidenceAgent on Llama-3.1-8b evaluates each tool result in a tight loop. RootCauseAgent on Llama-3.1-70b synthesizes confirmed evidence. CriticAgent on Gemini (gemini-2.0-flash, Google) red-teams the conclusion from a completely independent provider - falling back to Qwen-32b if Gemini quotas are exhausted. ReportAgent on Llama-3.1-70b writes the final document. VisionAgent on Gemini 2.5 Flash reads dashboard screenshots before text reasoning begins. The CriticAgent uses a different model family AND a different provider specifically so it cannot self-validate. Llama reasons on Vultr. Gemini challenges it from Google. Correlated reasoning errors become structurally impossible. The investigation is rejection-first by design. Hypothesis 1 is always a red herring. The agent must reject it with evidence before proceeding, forcing visible reasoning instead of shortcuts to the answer. Every tool call hits a real HTTP endpoint. Tool calls are observable in server access logs. Five incident scenarios from $21K to $312K. PagerDuty webhook triggers fully autonomous investigations. Deployed on Vultr with Docker Compose and SSE-tuned nginx.
19 May 2026
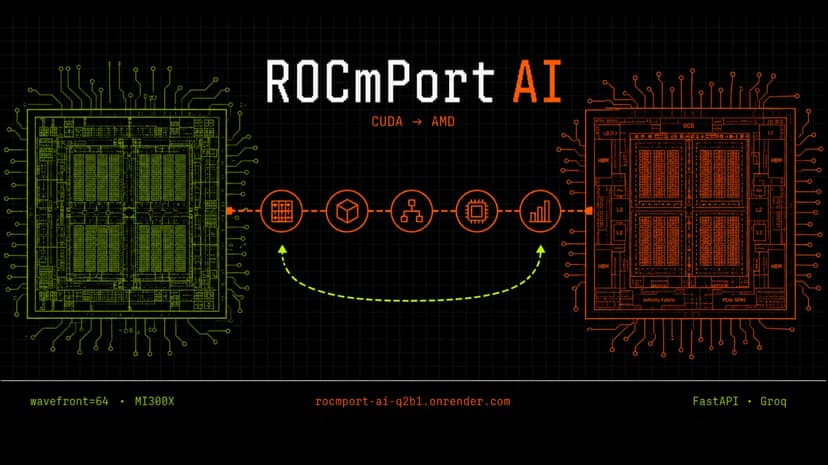
ROCmPort AI
CUDA-to-ROCm migration fails not at translation but at correctness. hipify-clang renames APIs mechanically. It cannot detect that a reduction kernel assuming warpSize=32 will silently produce wrong results on AMD wavefront-64. Lanes 32 through 63 are skipped. The code compiles. The output is wrong. Nobody tells you. ROCmPort AI is a closed-loop agentic system built to catch exactly this class of bug before it reaches production. The pipeline runs five agents in sequence. The Analyzer performs a static scan before any LLM call, grounding the system in what is actually in the code. The Translator runs hipify-clang as a first pass then applies LLM corrections for architecture-specific issues the tool cannot handle. The Optimizer applies MI300X-specific changes: wavefront-64 alignment, LDS bank conflict padding, shared memory tiling. The Tester compiles with hipcc and profiles with rocprof on real AMD hardware. The Coordinator evaluates the profiler output and decides whether to iterate or finalize. All four demo kernels were compiled and profiled on a real AMD Instinct MI300X on AMD Developer Cloud. gfx942. ROCm 7.2. data_source: "mi300x_live" The primary model is Qwen2.5-Coder-32B-Instruct, purpose-built for code reasoning tasks. Groq LLaMA-3.3-70B handles log parsing as a cost-efficient fallback. In production, Qwen runs via vLLM on the MI300X instance itself. Failure cases are documented explicitly, including library-heavy CUDA using CUB, Thrust, or cuDNN, which requires manual review after ROCmPort output. This is intentional. Credibility requires honesty about scope. The value is not speed. It is correctness before execution, and a decision trace that a senior engineer can audit.
10 May 2026

ArcReflex
Most agent payment demos show money moving. ArcReflex shows money being withheld, and that distinction is the whole point. The system runs five concurrent FastAPI microservices: two search agents, two filter agents, and a fact-check agent. An orchestrator picks between them based on live reputation scores and per-query pricing. When an agent returns acceptable results, the orchestrator releases a sub-cent USDC nanopayment via Circle's infrastructure. When results fall below the quality threshold, the payment is blocked, the agent's reputation takes a hit, and the task gets rerouted to the backup. The fact-check agent sits behind x402 middleware, so it will not accept any request that does not arrive with a valid payment receipt. No receipt, no access, full stop. To prove this is deterministic and not just a happy path demo, ArcReflex ships a judge mode. One command triggers a forced red-team scenario: Search Agent A degrades, the orchestrator catches it, withholds the payment, fails over to Agent B, and writes a SHA-256 signed evidence bundle to disk. An independent verifier script checks the bundle without importing any orchestrator code. The hashes either match or they do not. AgentRegistry.vy is the on-chain ledger that tracks agent addresses, reputation, and status on Arc. All settlement uses USDC. The frontend connects via WebSocket and shows payment events, quality gate decisions, and agent switching in real time, with a dedicated judge tab for exporting the evidence. The margin math is simple: at $0.0002 per query across 50+ transactions, traditional gas fees would cost more than the payments themselves. Nanopayments on Arc make the model viable. Gas fees on any other chain would kill it.
26 Apr 2026




