.png&w=256&q=75)
🤓 Latest Submissions
SceneIQ
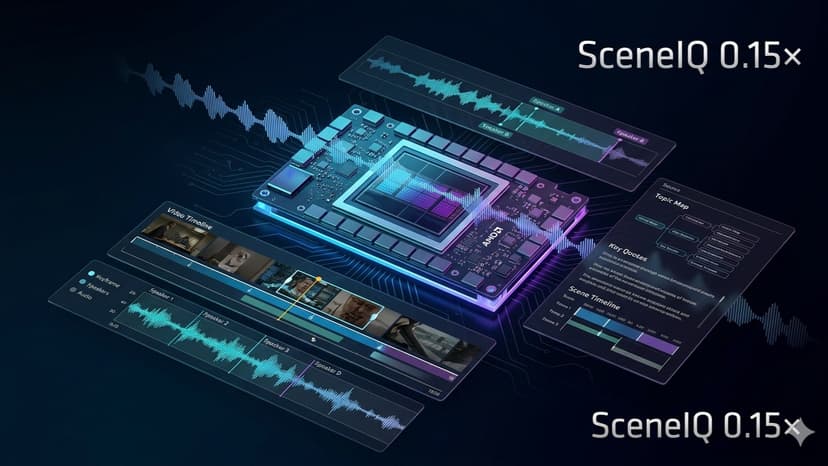
SceneIQ converts long-form video — senate hearings, webinars, podcasts, technical lectures — into structured intelligence dossiers at a fraction of real-time. Processing a 3-hour video in under 30 minutes, SceneIQ achieves a 0.15× real-time factor on a single AMD MI300X by running vision and audio in parallel rather than sequentially. The pipeline uses Qwen3-VL-32B-Thinking for adaptive keyframe analysis and synthesis, and Microsoft VibeVoice-ASR-HF for speaker-attributed transcription — both served via vLLM on ROCm. An adaptive keyframe selector reduces a 3-hour stream to as few as 40–60 visually distinct moments, cutting vision cost by over 90% while preserving meaningful content changes. Audio is transcribed concurrently so the two passes overlap, not stack. The output is a rich dossier: executive brief, topic map with timestamps, per-speaker claims, best quotes, highlight clip suggestions, repurposable social posts, and a benchmark card showing exact real-time factor, frames analyzed vs. skipped, and model stack. Everything streams live to a React UI via SSE as the MI300X works, giving a real-time window into the inference process. SceneIQ is designed for journalists, researchers, policy analysts, and content teams who need to extract signal from video at a scale that human review cannot match.
10 May 2026
